SPATIO-TEMPORAL
Information

Spatio-Temporal
In physics, spacetime is any mathematical model which fuses the three dimensions of space and the one dimension of time into a single four-dimensional manifold. Spacetime diagrams can be used to visualize relativistic effects, such as why different observers perceive differently where and when events occur.
A spatiotemporal database is a database that manages both space and time information. Common examples include:
- Tracking of moving objects, which typically can occupy only a single position at a given time.
- A database of wireless communication networks, which may exist only for a short timespan within a geographic region.
- An index of species in a given geographic region, where over time additional species may be introduced or existing species migrate or die out.
- Historical tracking of plate tectonic activity.
Publication
- Minkyu Kim and Suan Lee
- Big Data and Smart Computing (BigComp), 2021 IEEE International Conference on. IEEE, 2021.
- January 17-20, 2021
Abstract
Those who want to start their own businesses must decide a location and service to start. In order to make the decision, they must know characteristics of the location and service, such as average revenues and floating population. However, it is usually very difficult to collect and analyze these characteristics. Therefore, we propose a novel deep learning model named Neural Tensor Factorization (NeuralTF) that automatically analyzes the characteristics for predicting revenues, and a method for recommending appropriate location or service to start their businesses based on the predicted revenues. NeuralTF is a combination of Tensor Factorization(TF) and Deep Neural Network(DNN). We compare NeuralTF with other machine learning models using Seoul Commercial Alley dataset. In addition, we compare performances of NeuralTF when TF and DNN components share the embedding space and when they do not.
Keywords
Recommender System, Tensor Factorization, Neural Network, Deep Learning, Neural Tensor Factorization
- Minkyu Kim, Suan Lee, and Jinho Kim
- 2020 IEEE International Conference on Big Data (IEEE BigData 2020)
- December 10-13, 2020
Abstract
Regression analysis is one of the most widely used data analysis methods, and it is increasingly important to obtain accurate results from it. To obtain accurate prediction results of regression analysis through machine learning, we must select appropriate features and train various feature interactions. The combinatorial model consists of a combination of various subordinate components and is used for automatic training of various feature interactions. However, existing combinatorial models are inefficient b ecause t hey c an t rain o nly limited feature interactions and must combine several components. To overcome these limitations, this study proposes a new model called eXtreme Interaction Network (XIN). XIN can automatically learn various explicit interactions, various levels of implicit higher-order interactions, and polynomial features. We compared the proposed XIN with existing models using four datasets with different characteristics to demonstrate that the proposed model has higher performance and lower or comparable time and space complexities. Furthermore, we conducted experiments while changing the various hyper-parameters of the XIN and demonstrated the improved performance of the proposed method in various environments.
Keywords
Neural Networks, Deep Learning, Cross Network, Combinatorial Model, Feature Interactions
- Svetlana Kim, Suan Lee, Jinho Kim, and Yong-Ik Yoon
- The Journal of Supercomputing
- October 2020
Abstract
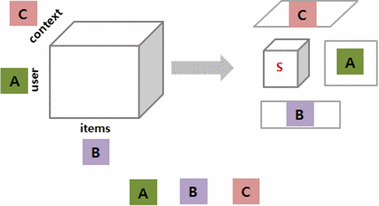
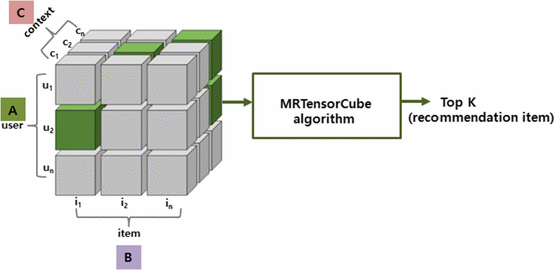
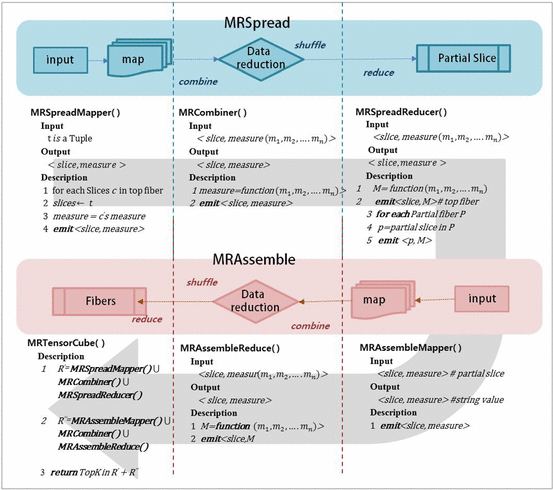
Context information can be an important factor of user behavior modeling and various context recognition recommendations. However, state-of-the-art context modeling methods cannot deal with contexts of other dimensions such as those of users and items and cannot extract special semantics. On the other hand, some tasks for predicting multidimensional relationships can be used to recommend context recognition, but there is a problem with the generation recommendations based on a variety of context information. In this paper, we propose MRTensorCube, which is a large-scale data cube calculation based on distributed parallel computing using MapReduce computation framework and supports efficient context recognition. The basic idea of MRTensorCube is the reduction of continuous data combined partial filter and slice when calculating using a four-way algorithm. From the experimental results, it is clear that MRTensor is superior to all other algorithms.
Keywords
Context awareness, Tensor data cube, MapReduce framework
- 박수경, 라시드, 이철기, 이수안, 이우기
- 한국컴퓨터종합학술대회, 한국정보과학회
- 2020년 07월
Abstract
최근 코로나 바이러스가 전세계적으로 확산됨에 따라 이를 차단하기 위한 많은 노력이 계속되고 있다. 국내에서는 COVID-19 확진 환자의 이동경로를 감염관리에 활용하고 있으며, 이 때 개인 정보 보호 차원에서 거주지 주소와 같은 세부 정보는 공개하지 않는다. 이와 같은 제한된 정보 공개는 국민들의 자가 감염 예방 활동이 제약되는 난점뿐만 아니라 여전한 개인 사생활 침해 가능성이란 문제점을 가진다. 본 연구에서는 이를 해결하기 위해 개인을 식별할 수 있는 위치 정보를 삭제하지 않고도 해당 데이터에 노이즈를 추가하는 익명화 방식을 통해 결과적으로 프라이버시를 보호할 수 있는 모델을 제안한다.
Keywords
- Minkyu Kim, Suan Lee, and Jinho Kim
- Big Data and Smart Computing (BigComp)
- February 19-22, 2020
Abstract
Wide & Deep model is deep learning model that jointed between of wide component and deep component for regression, recommendation, and classification. However, there is no study of regression analysis using Wide & Deep model. Also, Wide component of Wide & Deep model only deal with categorical variables and that need hand-crafted variables for efficient training. Therefore, this paper propose Lattice Wide & Deep Architecture which improve Wide & Deep model. Furthermore we show that the Lattice Wide & Deep model has better performance than Wide & Deep model in regression analysis.
Keywords
lattice wide & deep, wide & deep learning, regression analysis
- SungJin Park, Suan Lee, and Jinho Kim
- Big Data and Smart Computing (BigComp)
- February 19-22, 2020
Abstract
As for people who wish to start their own businesses, their concerns are whether they could survive during their operations because most stores or services in Seoul are not able to survive for more than 5 year possibly due to the poor decision of location/service to start. In order to solve this problem, using big data could be helpful to increase the survival rate. Singular Value Decomposition (SVD) has been widely used in finding the similarity between all pairs of alleys and obtaining predictions from unknown relevance scores. Since tensor decomposition is the extension of SVD for multi-dimensional data, using this method to find the similarity between all pair of alleys could be the solution of increasing survival rate. This paper aims to generate good prediction tensor, TENSORCABS, that is able to recommend users appropriate alley location to start their businesses or the appropriate services to start at the user’s desired location. Both CP and Tucker decompositions are used and compared to evaluate which method has better performance. Also, r-square for regression problem and precision & recall for top-k recommendation performance are used to evaluate the TENSORCABS. As results, actual and predicted values are good-fitted, and prediction tensor performs well on the top-k recommendation. In addition, Tucker outperforms CP for this situation. Therefore, the proposed method has advantages that can handle high-dimensional data and can use decomposition for recommendations of various perspectives. With this method, users are able to obtain recommendations of the appropriate alleys with predicted revenues for opening any business service or the appropriate services with predicted revenues on a user’s desired alley location.
Keywords
Recommendation System, Tucker Decomposition, Canonical Polyadic, Collaborative Filtering, Top-k Recommendation, Tensor, Commercial Alley
- 김민규, 이수안, 김진호
- 한국컴퓨터종합학술대회, 한국정보과학회
- 2019년 7월
Abstract
회귀분석은 시간에 따라 변화하는 데이터의 예측에 많이 이용되는 방법 중에 하나이다. 기존의 Wide & Deep 모델은 추천시스템에서 뛰어난 성능을 내는 방법이지만 회귀분석에서는 좋은 성능을 내지 못한다. 따라서 본 논문에서는 기존의 Wide & Deep 모델을 개선하여 회귀분석에서 잘 동작하는 Shared Wide & Deep 모델을 제안하였다. 제안한 모델을 검증하기 위해 여러 데이터들을 기존의 Wide & Deep 모델 그리고 다양한 회귀 분석 모델들과 비교하였다. 제안한 모델이 다른 모델들보다 높은 R^2 값을 가지고, 효율적으로 회귀 분석이 수행됨을 실험을 통해 확인하였다.
- Suan Lee, Seok Kang, Jinho Kim, and Eun Jung Yu
- Cluster Computing
- 01 Feb. 2018
Abstract
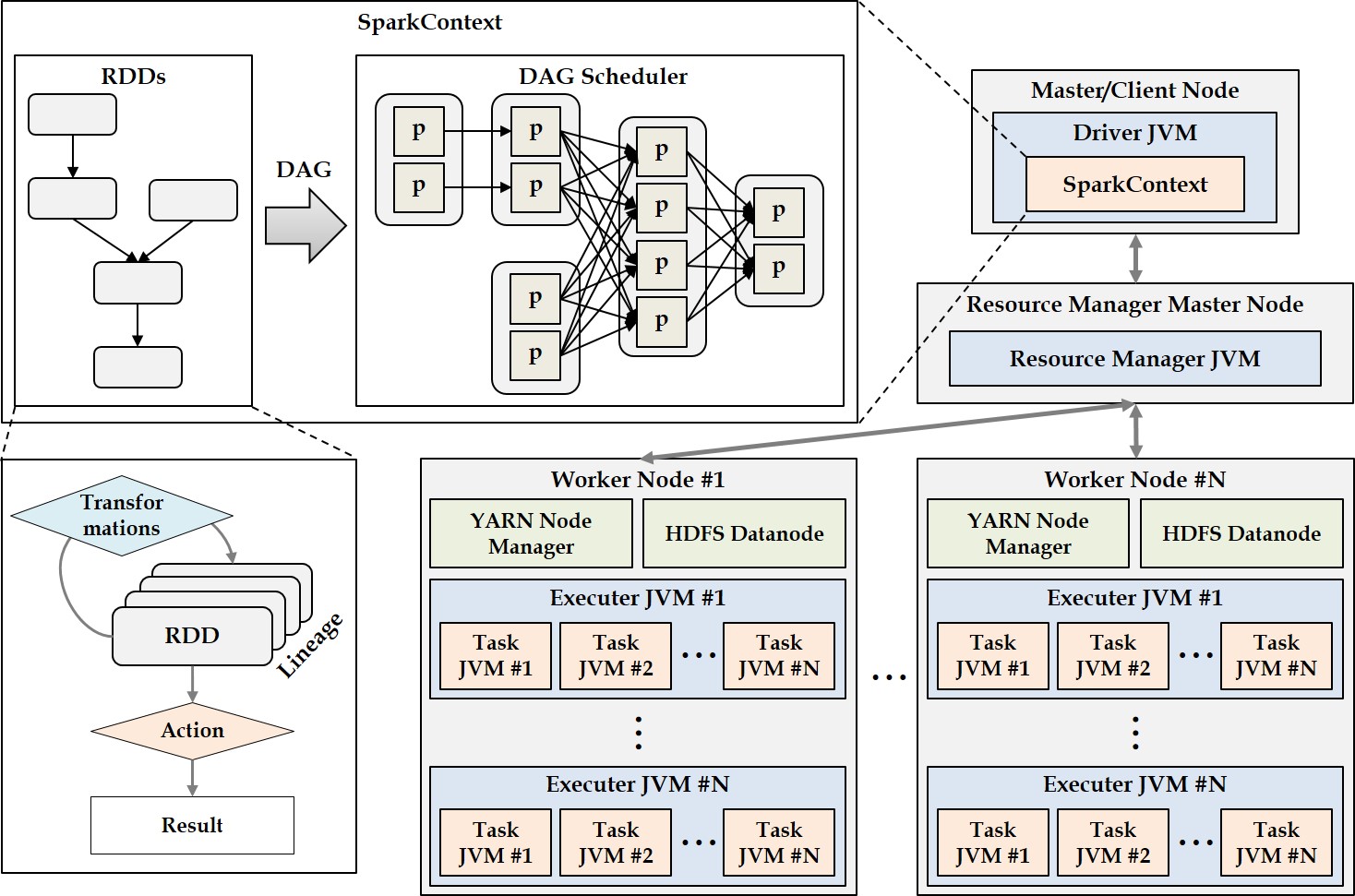
A data cube is a powerful analytical tool that stores all aggregate values over a set of dimensions. It provides users with a simple and efficient means of performing complex data analysis while assisting in decision making. Since the computation time for building a data cube is very large, however, efficient methods for reducing the data cube computation time are needed. Previous works have developed various algorithms for efficiently generating data cubes using MapReduce, which is a large-scale distributed parallel processing framework. However, MapReduce incurs the overhead of disk I/Os and network traffic. To overcome these MapReduce limitations, Spark was recently proposed as a memory-based parallel/distributed processing framework. It has attracted considerable research attention owing to its high performance. In this paper, we propose two algorithms for efficiently building data cubes. The algorithms fully leverage Spark’s mechanisms and properties: Resilient Distributed Top-Down Computation (RDTDC) and Resilient Distributed Bottom-Up Computation (RDBUC). The former is an algorithm for computing the components (i.e., cuboids) of a data cube in a top-down approach; the latter is a bottom-up approach. The RDTDC algorithm has three key functions. (1) It approximates the size of the cuboid using the cardinality without additional Spark action computation to determine the size of each cuboid during top-down computation. Thus, one cuboid can be computed from the upper cuboid of a smaller size. (2) It creates an execution plan that is optimized to input the smaller sized cuboid. (3) Lastly, it uses a method of reusing the result of the already computed cuboid by top-down computation and simultaneously computes the cuboid of several dimensions. In addition, we propose the RDBUC bottom-up algorithm in Spark, which is widely used in computing Iceberg cubes to maintain only cells satisfying a certain condition of minimum support. This algorithm incorporates two primary strategies: (1) reducing the input size to compute aggregate values for a dimension combination (e.g., A, B, and C) by removing the input, which does not satisfy the Iceberg cube condition at its lower dimension combination (e.g., A and B) computed earlier. (2) We use a lazy materialization strategy that computes every combination of dimensions using only transformation operations without any action operation. It then stores them in a single action operation. To prove the efficiency of the proposed algorithms using a lazy materialization strategy by employing only one action operation, we conducted extensive experiments. We compared them to the cube() function, a built-in cube computation library of Spark SQL. The results showed that the proposed RDTDC and RDBUC algorithms outperformed Spark SQL cube().

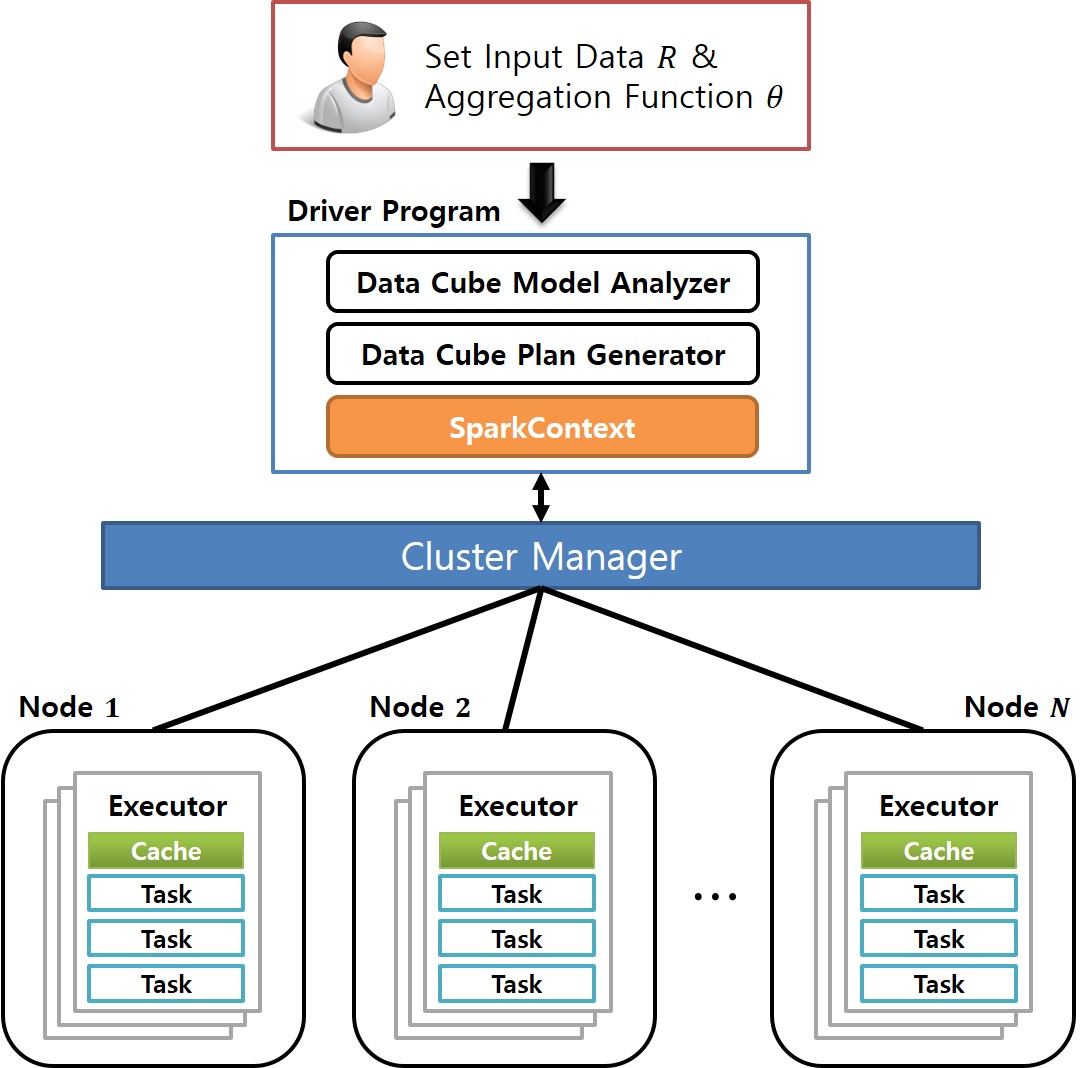
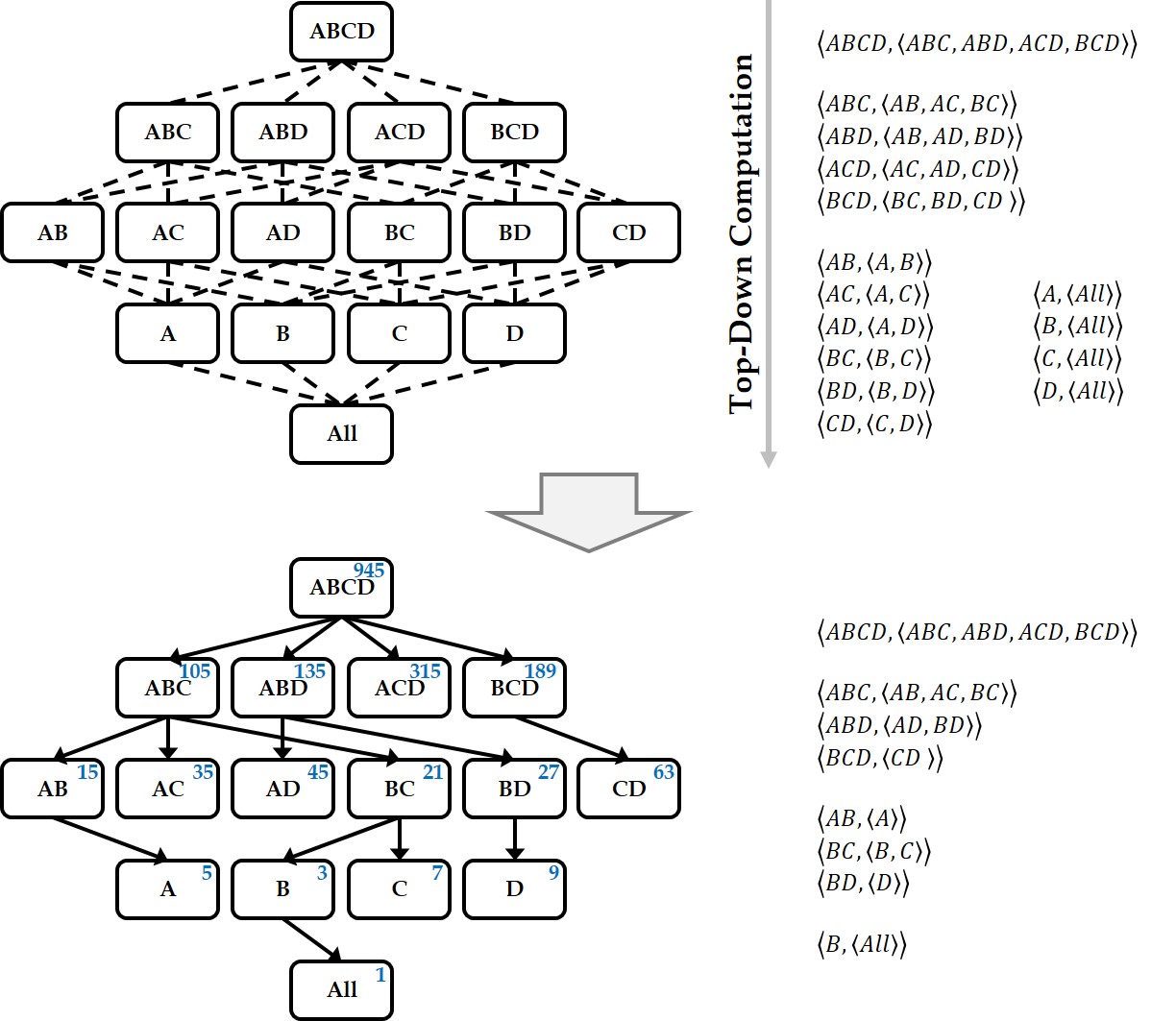
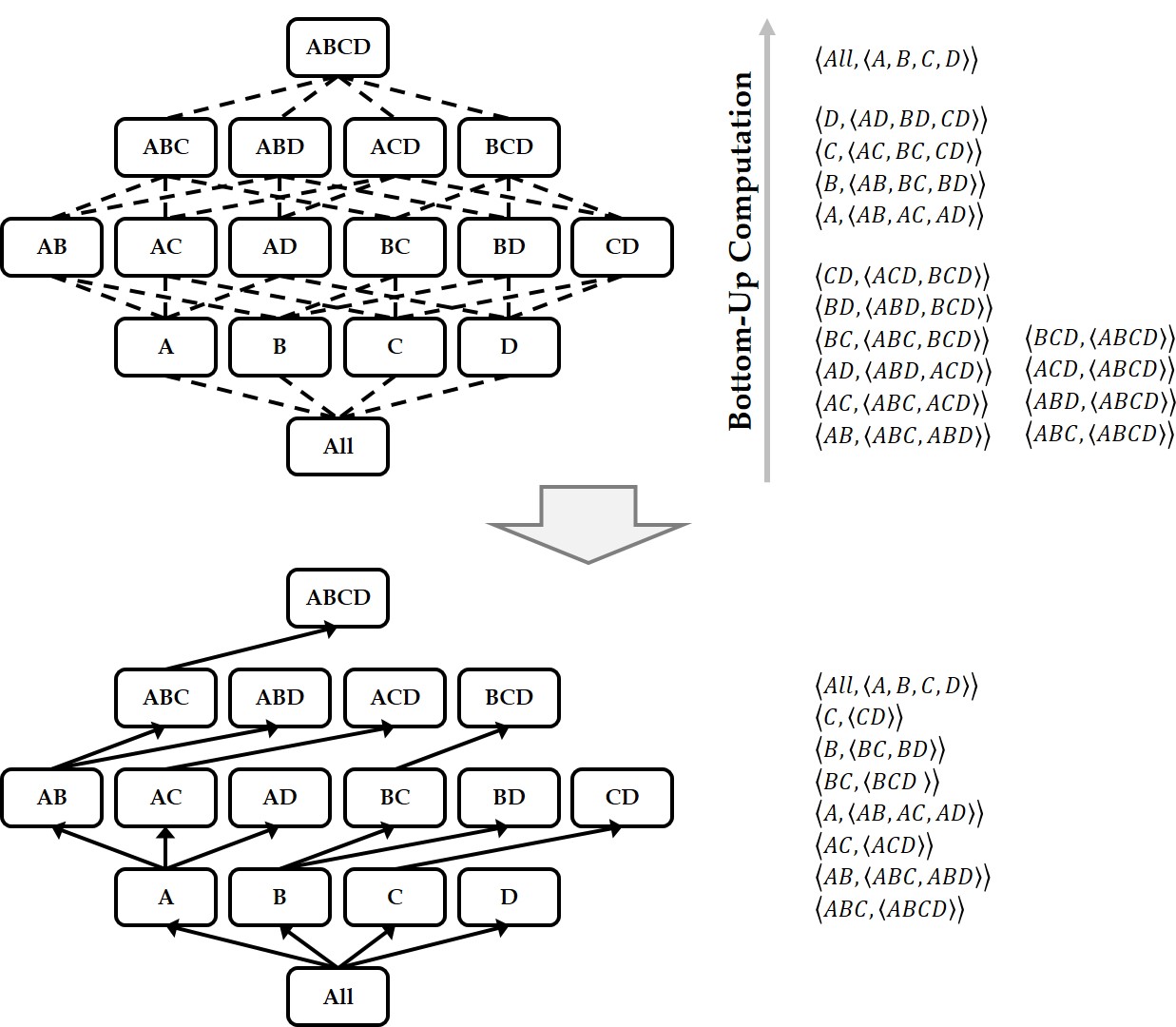
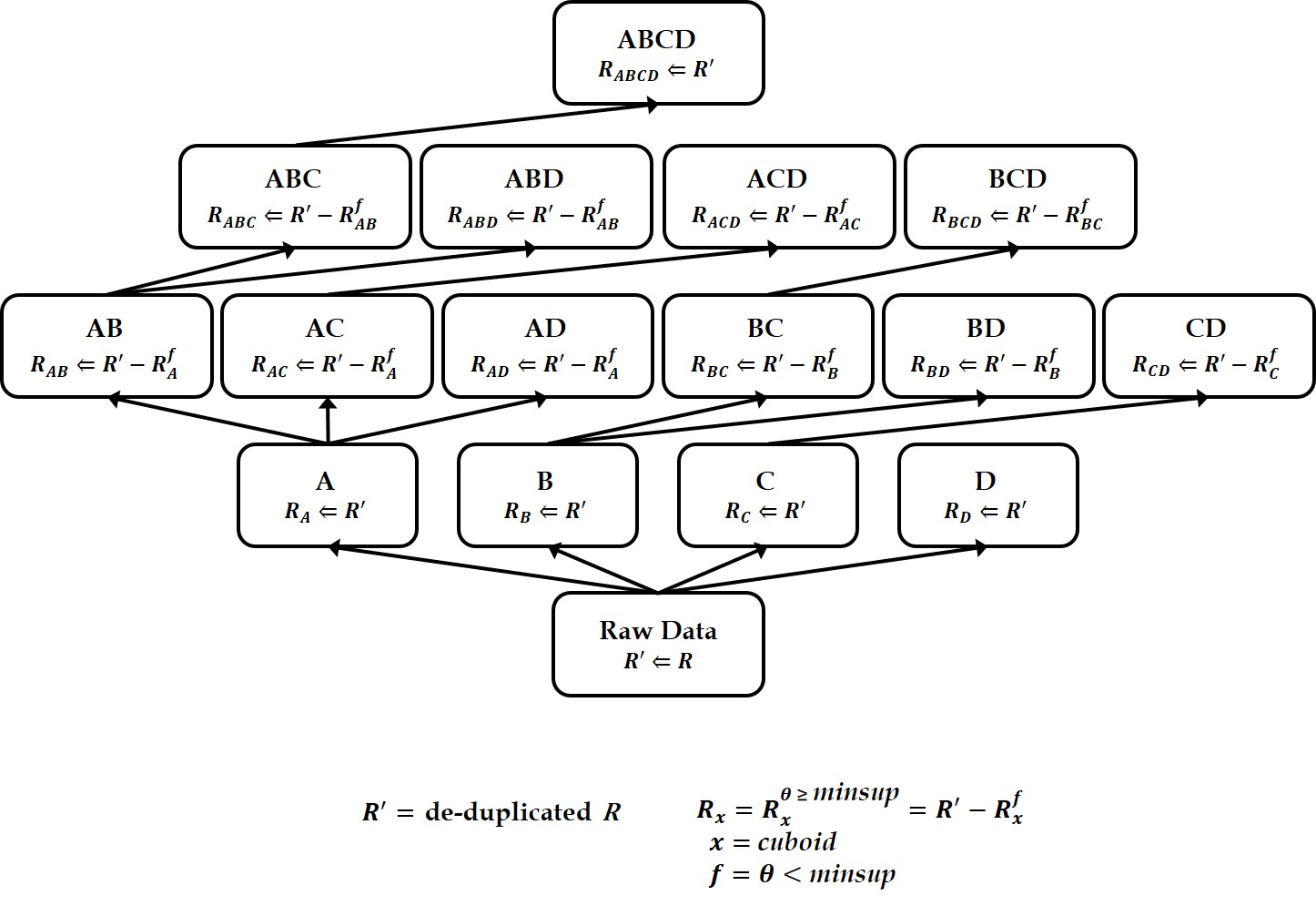
Keywords
Distributed processing, Spark framework, Resilient distributed dataset, Data warehousing, On-line analytical processing, Multidimensional data cube, Iceberg cube
- Suan Lee, Sunhwa Jo, Ji-Seop Won, Jinho Kim, and Yang-Sae Moon
- Applied Mathematics & Information Sciences
- 1 May 2015
Abstract
Recently new mobile devices such as cellular phones, smartphones, and digital cameras are popularly used to take photos. By virtue of these convenient instruments, we can take many photos easily, but we suffer from the difficulty of managing and searching photos due to their large volume. This paper develops a mobile application software, called Photo Cube, which automatically extracts various metadata for photos (e.g., date/time, address, place name, weather, personal event, etc.) by taking advantage of sensors and programming functions embedded in mobile smartphones like Android phones or iPhones. To avoid heavy network traffic and high processing overhead, it clusters photos into a set of clusters hierarchically by GPSs and it extracts the metadata for each centroid photo of clusters automatically. Then it constructs and stores the hierarchies of clusters based on the date/time, and address within the extracted metadata as well as the other metadata into photo database tables in the flash memory of smartphones. Furthermore, the system builds a multidimensional cube view for the photo database, which is popularly used in OLAP(On-Line Analytical Processing) applications and it facilitates the top-down browsing of photos over several dimensions such as date/time, address, etc. In addition to the hierarchical browsing, it provides users with keyword search function in order to find photos over every metadata of the photo database in a user-friendly manner. With these convenient features of the Photo Cube, therefore, users will be able to manage and search a large number of photos easily, without inputting any additional information but with clicking simply the shutter in a camera.
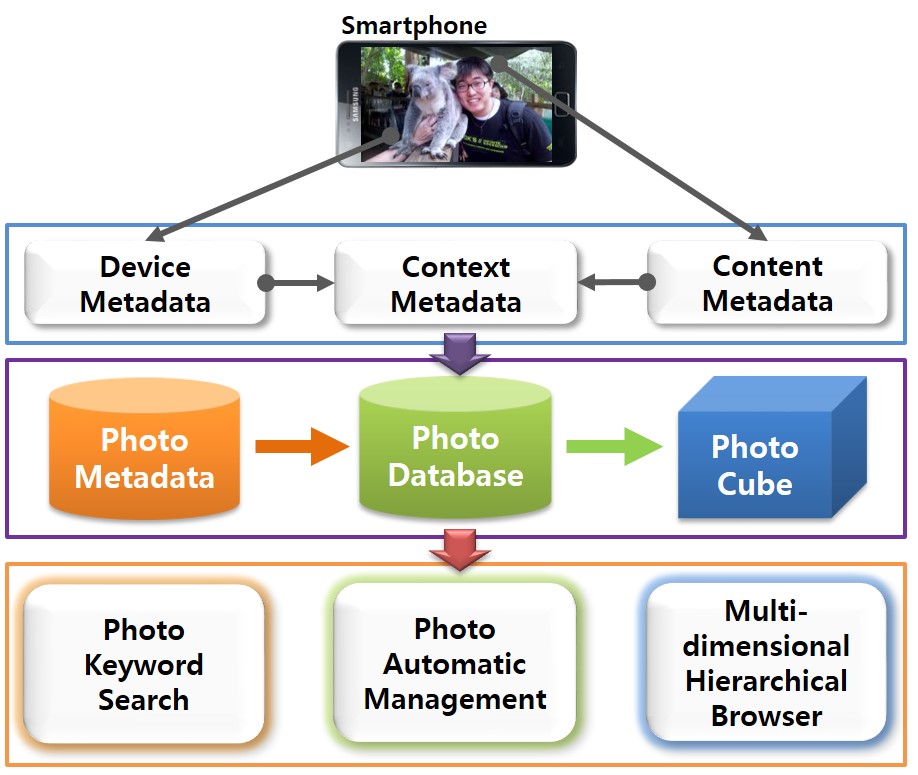

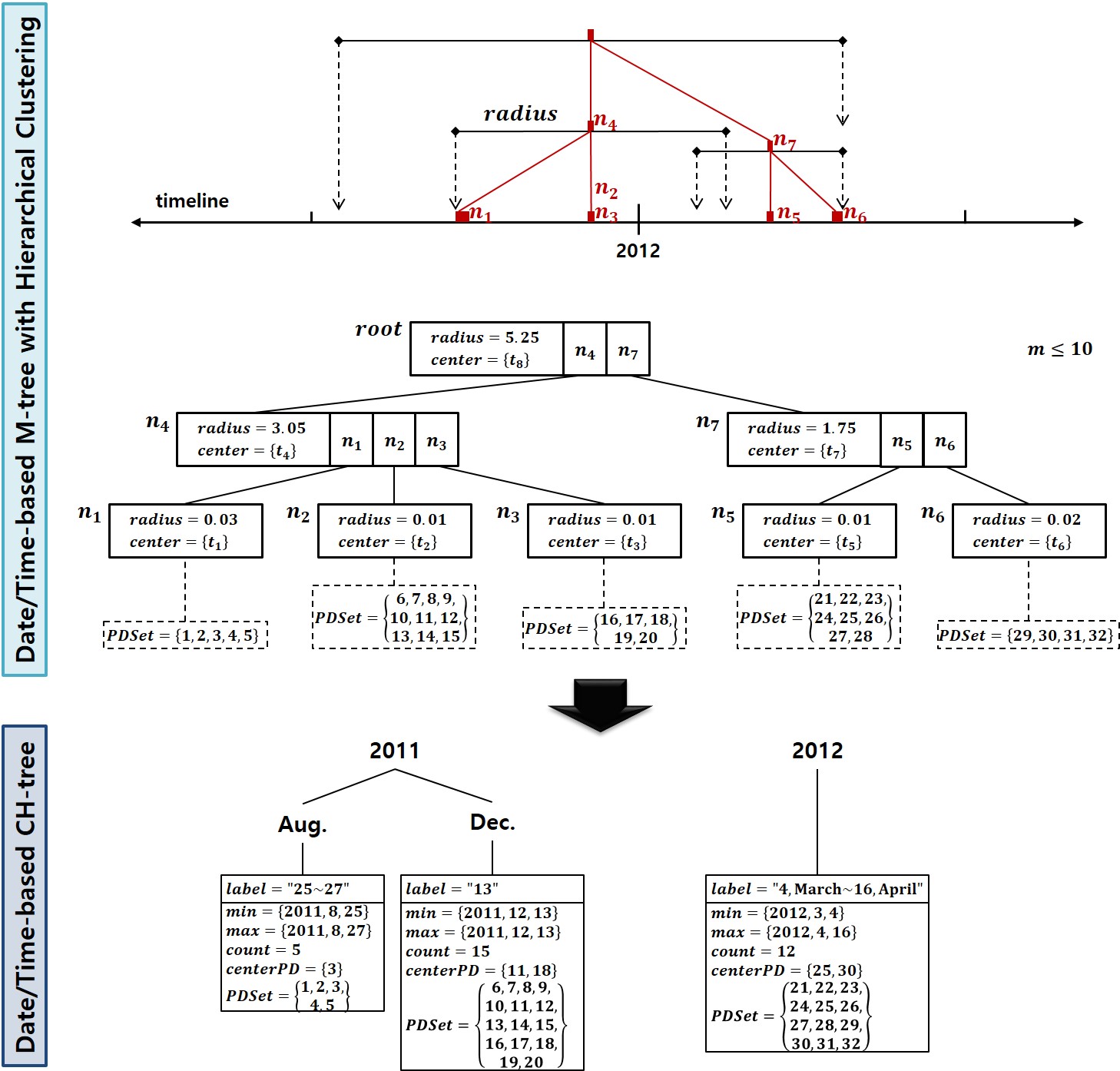
Keywords
photo metadata, photo annotation, clustered databases, multidimensional data cube, OLAP, hierarchical clustering, keyword search, multidimensional hierarchical browsing, mobile application, smartphones
- Suan Lee, Sunhwa Jo, and Jinho Kim
- Big Data and Smart Computing (BigComp), 2015 International Conference on. IEEE
- 9-11 Feb. 2015
Abstract
Data cube is used as an OLAP (On-Line Analytical Processing) model to implement multidimensional analyses in many fields of application. Computing a data cube requires a long sequence of basic operations and storage costs. Exponentially accumulating amounts of data have reached a magnitude that overwhelms the processing capacities of single computers. In this paper, we implement a large-scale data cube computation based on distributed parallel computing using the MapReduce (MR) computational framework. For this purpose, we developed a new algorithm, MRDataCube, which incorporates the MR mechanism into data cube computations such that effective data cube computations are enabled even when using the same computing resources. The proposed MRDataCube consists of two-level MR phases, namely, MRSpread and MRAssemble. The main feature of this algorithm is a continuous data reduction through the combination of partial cuboids and partial cells that are emitted when the computation undergoes these two phases. From the experimental results we revealed that MRDataCube outperforms all other algorithms.
Keywords
distributed parallel algorithm, cube, OLAP, multi-dimensional analysis, data cube computation, MapReduce, Hadoop
- Suan Lee, Namsoo Kim, and Jinho Kim
- Big Data and Cloud Computing (BdCloud), 2014 IEEE Fourth International Conference on. IEEE
- 3-5 Dec. 2014
Abstract
Recently, unstructured data like texts, documents, or SNS messages has been increasingly being used in many applications, rather than structured data consisting of simple numbers or characters. Thus it becomes more important to analysis unstructured text data to extract valuable information for usres decision making. Like OLAP (On-Line Analytical Processing) analysis over structured data, Multi-dimensional analysis for these unstructured data is popularly being required. To facilitate these analysis requirements on the unstructured data, a text cube model on multi-dimensional text database has been proposed. In this paper, we extended the existing text cube model to incorporate TF-IDF (Term Frequency Inverse Document Frequrency) and LM (Language Model) as measurements. Because the proposed text cube model utilizes new measurements which are more popular in information retrieval systems, it is more efficient and effective to analysis text databases. Through experiments, we revealed that the performance and the effectiveness of the proposed text cube outperform the existing one.
Keywords
language model, OLAP, Multi-dimensional analysis, text cube, data cube, text databases, information retrieval, TF-IDF
- 김남수, 이수안, 조선화, 김진호
- 정보화연구, 한국엔터프라이즈아키텍처학회
- 2014년 03월 30일
Abstract
웹의 발달로 텍스트 등으로 이루어진 비정형 데이터의 활용에 대한 관심이 높아지고 있다. 웹 상에서 사용자들이 작성한 대부분의 비정형 데이터는 사용자의 주관이 담겨져있어 이를 적절히 분석 할 경우 사용자의 취향이나 주관적인 관점 등의 아주 유용한 정보를 얻을 수 있다. 이 논문에서는 이러한 비정형 텍스트 문서를 다양한 차원으로 분석하기 하는데 OLAP(온라인 분석 처리)의 다차원 데 이터 큐브 기술을 활용한다. 다차원 데이터 큐브는 간단한 문자나 숫자 형태의 정형적인 데이터에 대 해 다차원 분석하는데 널리 사용되었지만, 텍스트 문장으로 이루어진 비정형 데이터에 대해서는 활용 되지 않았다. 이러한 텍스트 데이터베이스에 포함된 정보를 다차원으로 분석하기 위한 방법으로 텍스 트큐브 모델이 최근에 제안되었는데, 이 텍스트 큐브는 정보 검색에서 널리 사용하는 용어 빈도수 (Term Frequency)와 역 인덱스(Inverted Index)를 측정값으로 이용하여 텍스트 데이터베이스에 대 한 다차원 분석을 지원한다. 이 논문에서는 이러한 다차원 텍스트 큐브를 활용하여 실제 서비스되고 있는 호텔 정보 공유 사이트의 리뷰 데이터 분석에 활용하였다. 이를 위해 호텔 리뷰 데이터에 대한 다차원 텍스트 큐브를 생성하였으며, 이를 이용하여 다차원 키워드 검색 기능을 제공하여 사용자 중 심의 의미있는 정보 검색이 가능한 시스템을 설계 및 구현하였다. 또한, 본 논문에서 제안하는 시스템 에 대해 다양한 실험을 수행하였으며 이를 통해 제안된 시스템의 실효성을 검증하였다. As the advance of WWW, unstructured data including texts are taking users' interests more and more. These unstructured data created by WWW users represent users' subjective opinions thus we can get very useful information such as users' personal tastes or perspectives from them if we analyze appropriately. In this paper, we provide various analysis efficiently for unstructured text documents by taking advantage of OLAP (On-Line Analytical Processing) multidimen-sional cube technology. OLAP cubes have been widely used for the multidimensional analysis for structured data such as simple alphabetic and numberic data but they didn't have used for unstructured data consisting of long texts. In order to provide multidimensional analysis for unstructured text data, however, Text Cube model has been proposed precently. It incorporates term frequency and inverted index as measurements to search and analyze text databases which play key roles in information retrieval. The primary goal of this paper is to apply this text cube model to a real data set from in an Internet site sharing hotel information and to provide multidimensional analysis for users' reviews on hotels written in texts. To achieve this goal, we first build text cubes for the hotel review data. By using the text cubes, we design and implement the system which provides multidimensional keyword search features to search and to analyze review texts on various dimensions. This system will be able to help users to get valuable guest-subjective summary information easily. Furthermore, this paper evaluats the proposed systems through various experiments and it reveals the effectiveness of the system.
Keywords
다차원 텍스트 데이터베이스, 텍스트 큐브, 온라인 다차원 분석, 사용자 리뷰 분석, 키워드 검색 Multi-dimensional Text Databases, Text Cubes, On-Line Analytical Processing (OLAP), Usres' review analysis, keyword search
- Jinho Kim, Suan Lee, Ji-Seop Won, and Yang-Sae Moon
- Dependable, Autonomic and Secure Computing (DASC), 2011 IEEE Ninth International Conference on. IEEE
- 12-14 Dec. 2011
Abstract
Recently new mobile devices such as cellular phones, smart phones, and digital cameras are popularly used to take photos. By the virtue of these convenient instruments, we can take many photos easily, but we suffer from the difficulty of managing and searching photos due to their large volume. This paper develops a mobile application software, called Photo Cube, which automatically extracts various metadata for photos (e.g., date/time, place/address, weather, personal event, etc.) by taking advantage of sensors and networking functions embedded in mobile smart phones like Android phones or iPhones. The metadata can be used to manage and to search photos. Using this Photo Cube, users will be able to classify, store, manage, and search a large number of photos easily, without specifying any information but just clicking the shutter in a camera. The Photo Cube system was implemented on smart phones using Google's Android.
Keywords
multidimensional search, photo metadata, photo annotation, image databases, mobile application, smartphones, text search