DATA SCIENCE & BIG DATA
Information

Data Science & Big Data
Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from structured and unstructured data, and apply knowledge and actionable insights from data across a broad range of application domains. Data science is related to data mining, machine learning and big data.
Data science is a "concept to unify statistics, data analysis, informatics, and their related methods" in order to "understand and analyze actual phenomena" with data. It uses techniques and theories drawn from many fields within the context of mathematics, statistics, computer science, information science, and domain knowledge. However, data science is different from computer science and information science. Turing Award winner Jim Gray imagined data science as a "fourth paradigm" of science (empirical, theoretical, computational, and now data-driven) and asserted that "everything about science is changing because of the impact of information technology" and the data deluge.
Publication
- Seok Kang, Suan Lee, and Jinho Kim
- Cluster Computing
- October 2020
Abstract
Graph OLAP is a technology that generates aggregates or summaries of a large-scale graph based on the properties (or dimensions) associated with its nodes and edges, and in turn enables interactive analyses of the statistical information contained in the graph. To efficiently support these OLAP functions, a graph cube is widely used, which maintains aggregate graphs for all dimensions of the source graph. However, computing the graph cube for a large graph requires an enormous amount of time. While previous approaches have used the MapReduce framework to cut down on this computation time, the recently developed Spark environment offers superior computational performance. To leverage the advantages of Spark, we propose the GraphNaïve and GraphTDC algorithms. GraphNaïve sequentially computes graph cuboids for all dimensions in a graph, while GraphTDC computes them after first creating an execution plan. We also propose the Generate Multi-Dimension Table method to efficiently create a multidimensional graph table to express the graph. Evaluation experiments demonstrated that the GraphTDC algorithm significantly outperformed Spark SQL’s built-in library DataFrame, as the size of graphs increased.

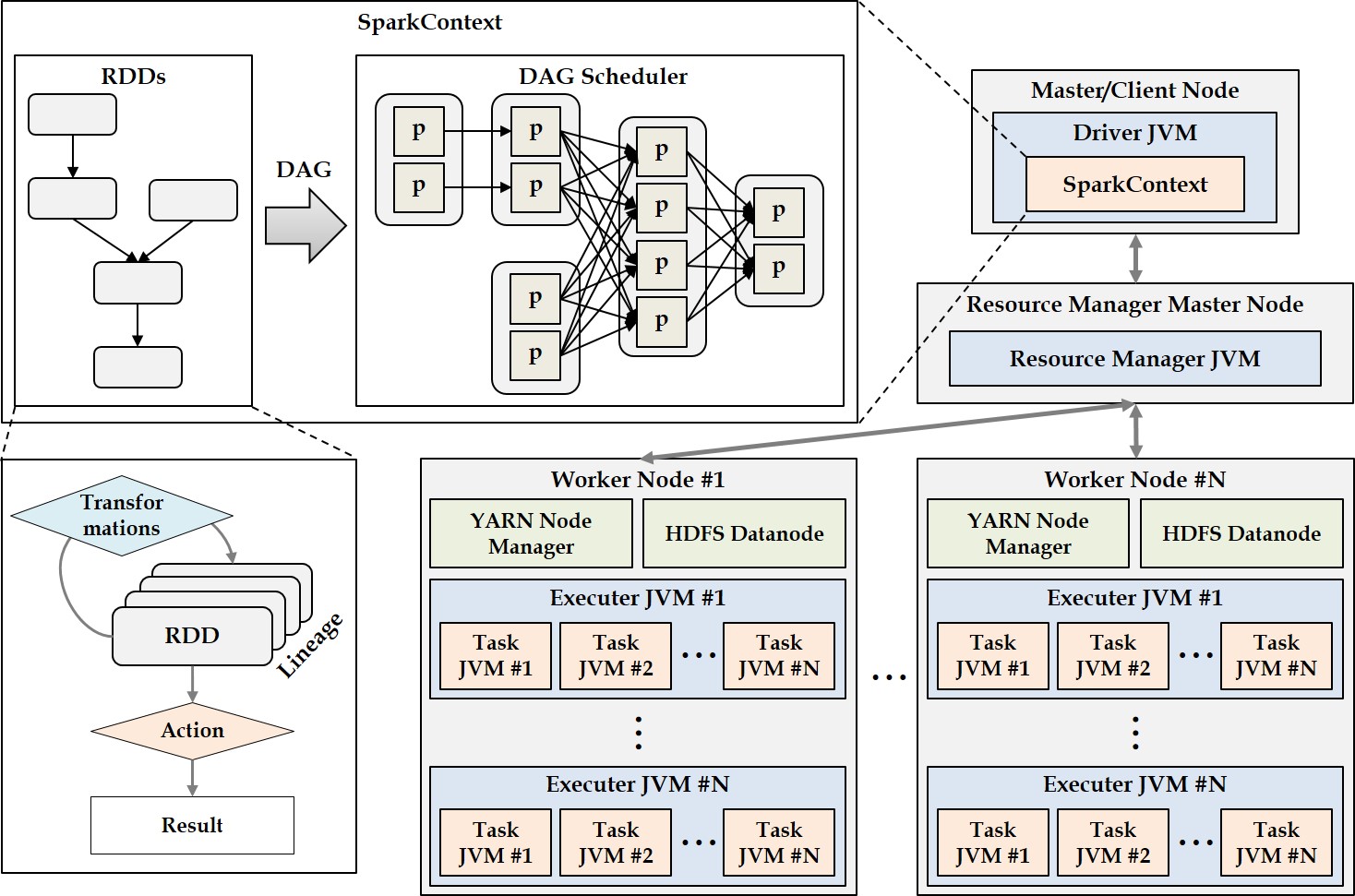
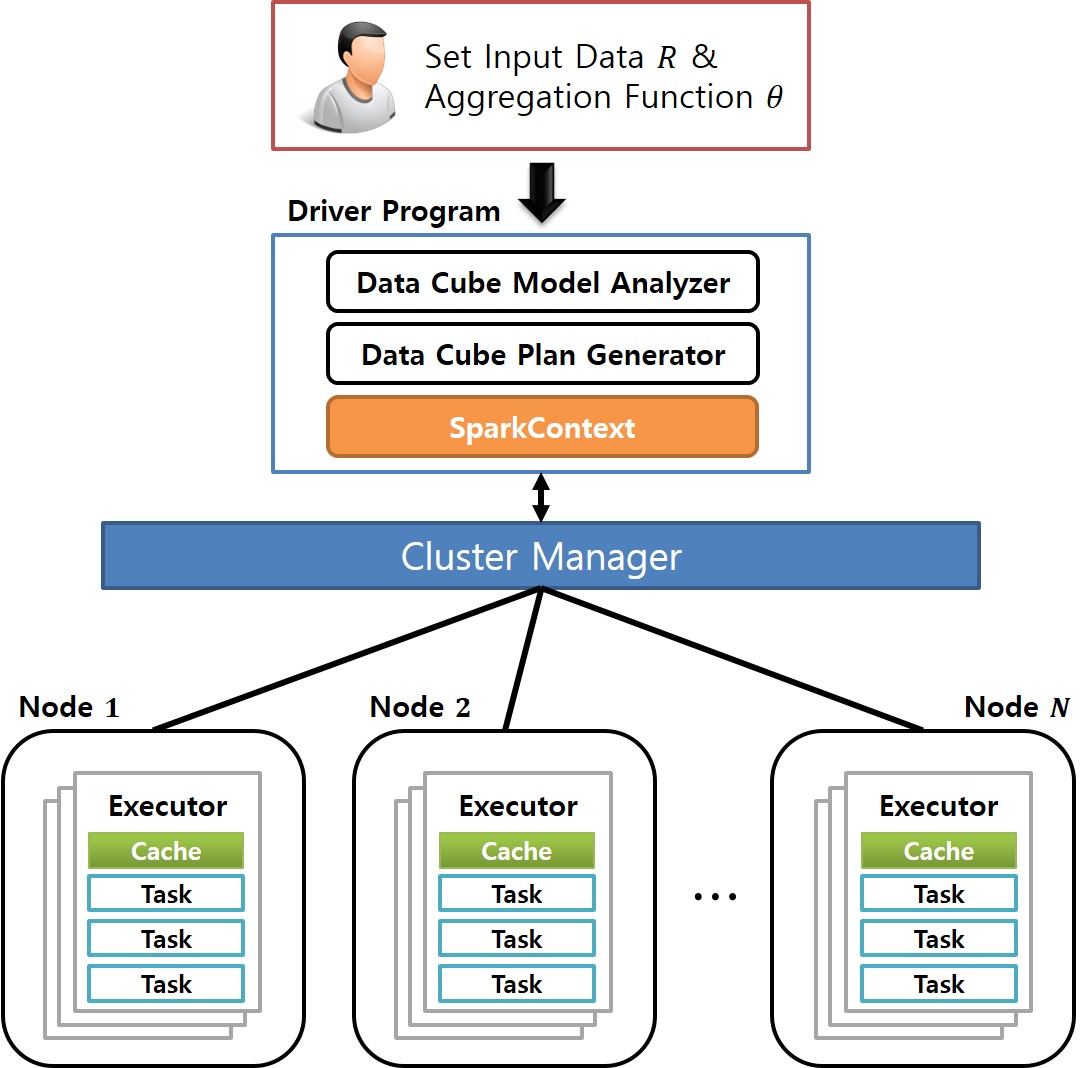
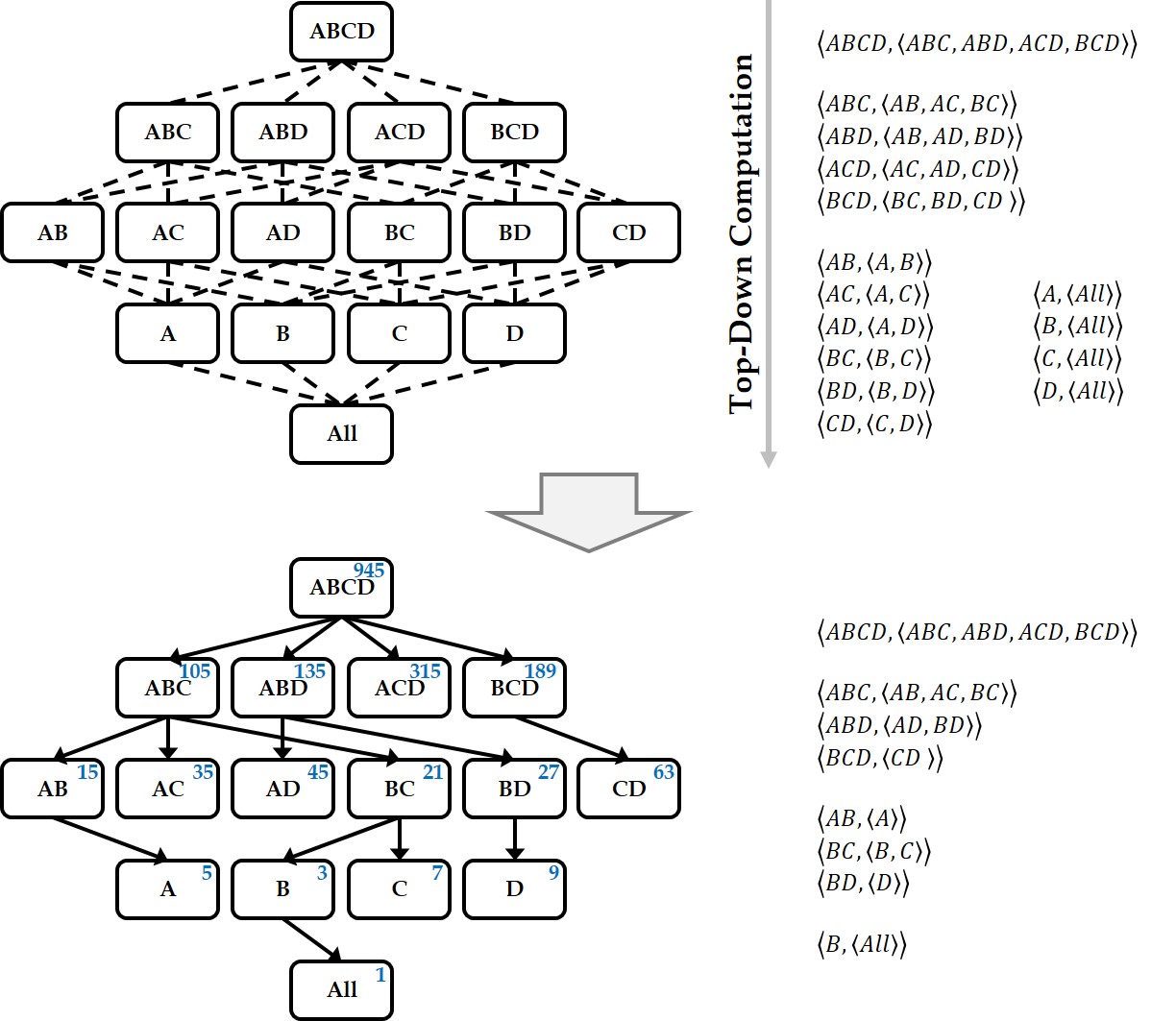
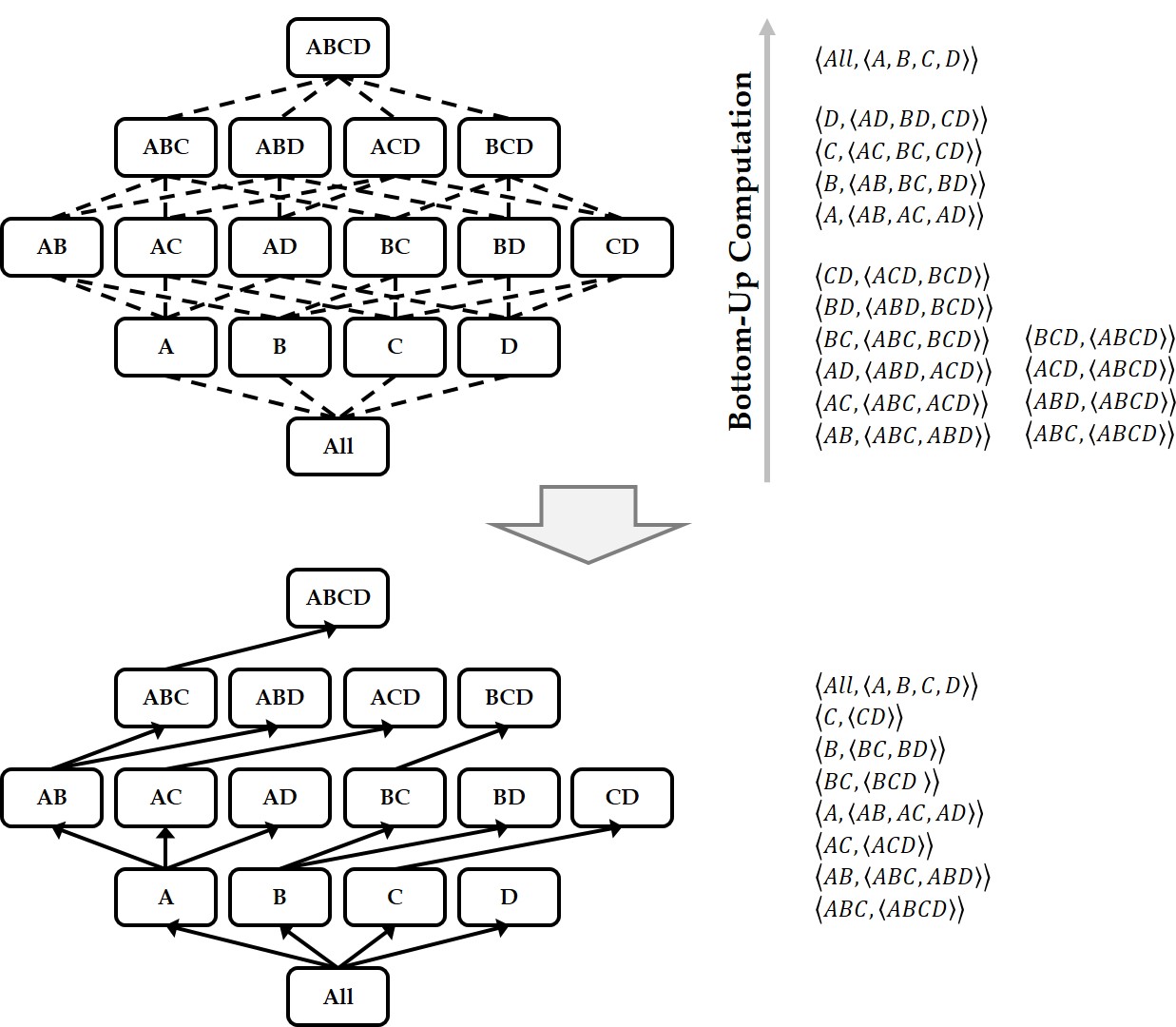
Keywords
Distributed parallel processing, Spark framework, Resilient distributed dataset, Graph cube, Data cube, Online analytical processing
- Svetlana Kim, Suan Lee, Jinho Kim, and Yong-Ik Yoon
- The Journal of Supercomputing
- October 2020
Abstract
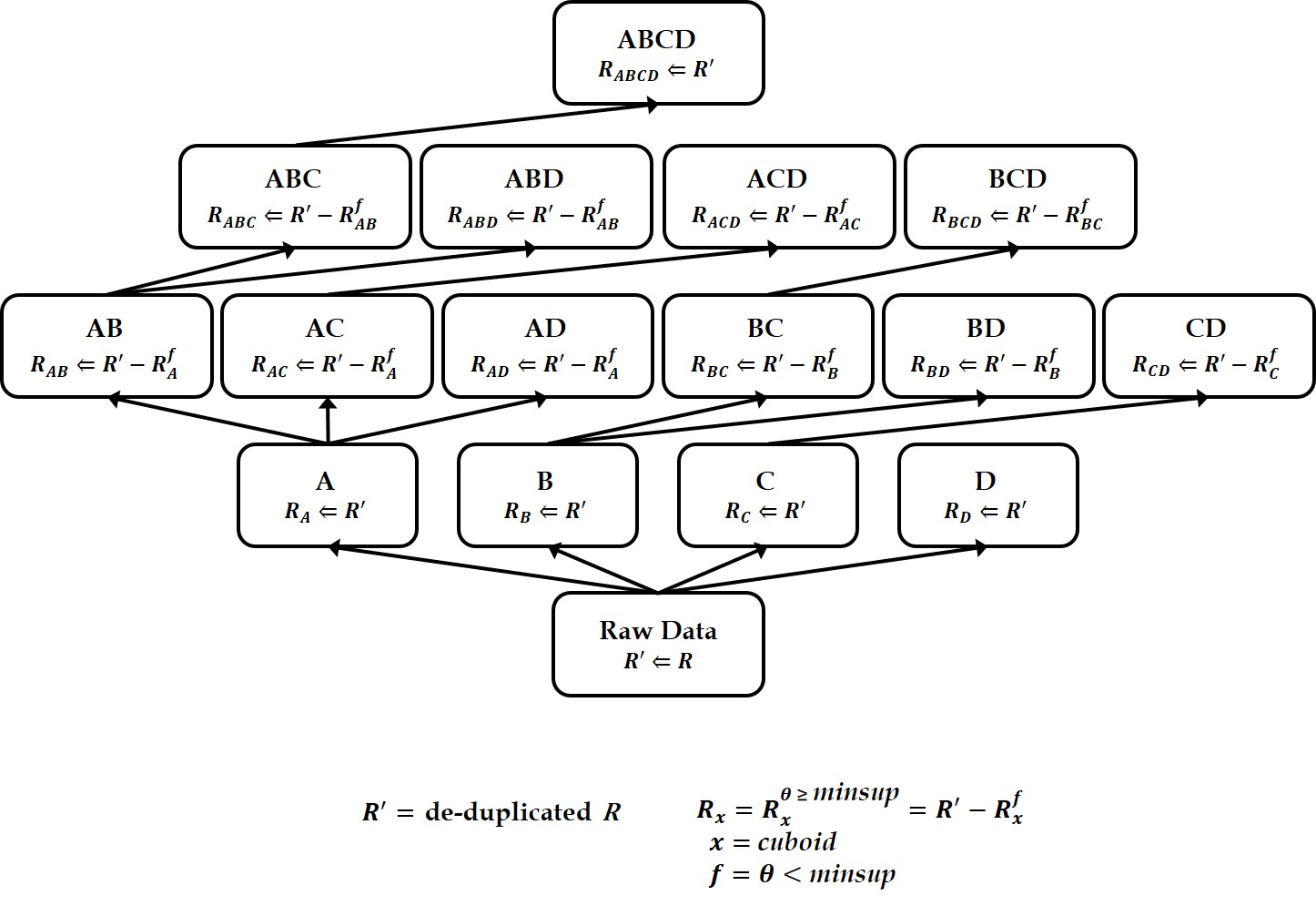
Context information can be an important factor of user behavior modeling and various context recognition recommendations. However, state-of-the-art context modeling methods cannot deal with contexts of other dimensions such as those of users and items and cannot extract special semantics. On the other hand, some tasks for predicting multidimensional relationships can be used to recommend context recognition, but there is a problem with the generation recommendations based on a variety of context information. In this paper, we propose MRTensorCube, which is a large-scale data cube calculation based on distributed parallel computing using MapReduce computation framework and supports efficient context recognition. The basic idea of MRTensorCube is the reduction of continuous data combined partial filter and slice when calculating using a four-way algorithm. From the experimental results, it is clear that MRTensor is superior to all other algorithms.
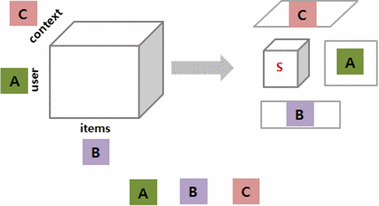
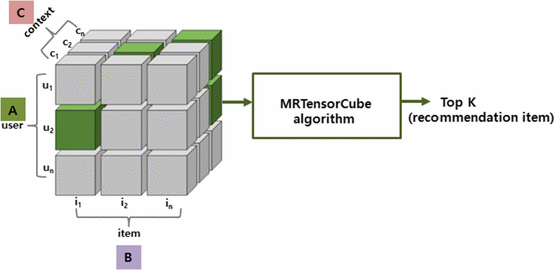
Keywords
Context awareness, Tensor data cube, MapReduce framework
- 박수경, 라시드, 이철기, 이수안, 이우기
- 한국컴퓨터종합학술대회, 한국정보과학회
- 2020년 07월
Abstract
최근 코로나 바이러스가 전세계적으로 확산됨에 따라 이를 차단하기 위한 많은 노력이 계속되고 있다. 국내에서는 COVID-19 확진 환자의 이동경로를 감염관리에 활용하고 있으며, 이 때 개인 정보 보호 차원에서 거주지 주소와 같은 세부 정보는 공개하지 않는다. 이와 같은 제한된 정보 공개는 국민들의 자가 감염 예방 활동이 제약되는 난점뿐만 아니라 여전한 개인 사생활 침해 가능성이란 문제점을 가진다. 본 연구에서는 이를 해결하기 위해 개인을 식별할 수 있는 위치 정보를 삭제하지 않고도 해당 데이터에 노이즈를 추가하는 익명화 방식을 통해 결과적으로 프라이버시를 보호할 수 있는 모델을 제안한다.
Keywords
- 고수윤, 이수안, 손경호
- 과학기술법연구, 한남대학교 과학기술법연구원
- 2020.05.01
Abstract
우리나라는 해외 주요국과 같이 개인정보에 대한 정보주체의 권리를 보장하고자 마이데이터 정책을 점차 확장하고 있다. 마이데이터는 정보주체 중심의 데이터 생태계를 형성하는 것을 목적으로 하고 있으며 데이터 이동에 대한 통제권을 정보주체에게 보장함으로써 이를 달성하고자 하였다. 데이터이동권을 처음으로 규정한 EU GDPR은 공정한 시장경쟁을 위한 것을 목적으로 하고 있으며 특히 데이터이동권은 정보주체가 특정 서비스에 락인(lock-in)되는 현상을 방지하여 다른 서비스로 이전할 수 있도록 보장하고자 한 권리이다. 실제 거대 IT기업들이 정보유통시장을 과점하는 것을 방지하려는 목적이 있었다. 동일한 이유로, 단일화되고 있는 디지털 시장에서 우리나라 기업의 유효경쟁을 보장하고 정보주체의 서비스 선택에 자율성을 보장하기 위해 데이터이동권을 보장하는 것이 필요하다. 우리나라에서 데이터이동권은 데이터 이동에 대한 정보주체의 통제권을 의미한다는 점에서 데이터를 받을 수 있는 권리, 동의를 결정할 권리, 데이터 제공을 요청할 권리라는 모든 경우에 해당될 수 있다. 하지만 데이터이동권을 처음으로 명시한 EU GDPR의 규정에 따르면 데이터이동권은 정보주체가 개인정보를 기계판독이 가능한 포맷으로 제공받을 권리이다. 기계판독이 가능한 포맷 또는 상호운용성 있는 포맷의 보장은 해당 데이터가 이전받은 컨트롤러에 의한 이용가능성을 보장하고자 하는 의도가 있다. 우리나라 데이터이동권의 권리범위도 데이터 활용을 보장하며 정보주체가 데이터의 제공을 적극적으로 요청할 수 있는 권리로 보는 것이 타당할 것이다. 개인정보 일반에 대하여는 해당 규정이 존재하지 않으므로 이를 보장하기 위해서는 규정의 신설이 필요하다. 구체적으로 데이터이동권 규정을 도입하기 위하여 권리제한사유, 데이터 제공자, 제공자의 의무, 대상 데이터의 범위, 정보제공방법, 데이터 이동 요청에 따른 처리기간, 처리비용에 대하여 해외 주요국의 규정과 비교검토해 본다. Korea is gradually expanding its MyData policy to ensure the right of the data subject to personal data like major foreign countries. My Data aims to form a data ecosystem centered on the data subject, and aims to achieve this by ensuring control over data portability by the data subject. The EU GDPR, which first stipulated the right to data portability, aims to promote fair market competition. In particular, the right to data portability is intended to prevent data subjects from being locked in to a specific service and to be able to transfer to another service. Indeed, it generated to prevent IT giants from dominating the information distribution market. For the same reason, it is necessary to guarantee the right to data portability in order to ensure the effective competition of Korean companies in a single digital market and to ensure the autonomy in the choice of services by data subjects. In Korea, the right to data portability can refer to all cases of the right to receive data, the right to decide consent, and the right to request data in that it means the right to control the data subject. However, according to the EU GDPR, the right to data portability is the right of the data subject to receive personal data in a machine-readable format. The guarantee of a machine-readable format or an interoperable format is intended to guarantee the availability of the transferred data by a controller. It would be appropriate to view the right scope of data portability in Korea as the right to guarantee the utilization of data and to actively request the controller to provide the personal data. In Korea, there is no provision for the right to data portability, it is necessary to establish a new provision to ensure this. Specifically, this paper compares the reasons for restriction of the right, the data provider, the obligations of the providers, the scope of the target data, the method of providing data, and the processing period and the processing cost according to the request for data porting with the regulations of foreign countries to introduce the provision for the right to data portability.
Keywords
데이터이동권, GDPR, 디지털공화국법, 기업 및 규제개혁법, 마이데이터 Data Portability, GDPR, Digital Republic Act, Enterprise and Regulatory Reform Act, MyData
- 손경호, 이수안, 고수윤
- 한국데이터산업진흥원
- 2019년 12월
개요
2012년 1월 25일 유럽위원회는 온라인상의 개인정보보호 권리를 강화하고 유럽의 디지털 경제를 강화하기 위해 EU의 1995년 데이터 보호 규칙에 대한 포괄적인 개혁을 제안했다. 이때 주요 개혁내용 중 하나로 데이터 이동권이 제시되었다. EU GDPR(General Data Protection Regulation) 제20조, 데이터 이동권(Right to data portability)은 자동수단을 통해 개인정보가 처리되는 경우, 정보 주체의 개인정보에 대한 통제권을 더욱 강화하기 위해 정보 주체 본인이 개인정보 처리자에게 제공한 개인정보를 체계적이고 일반적으로 사용하는 기계판독 및 상호 운용성(interoperability) 있는 포맷으로 받을 수 있거나 이를 또 다른 관리자에게 이전할 수 있는 권리이다.
- 장종원, 전호빈, 이수안, 김진호, 박홍성, 김미숙, 유수정, 지상훈
- 한국소프트웨어종합학술대회, 한국정보과학회
- 2019년 12월
Abstract
최근 빅데이터와 AI를 이용한 다양한 활용성이 주요한 이슈로 떠오르고 있다. 그중에는 수많은 영상을 데이터로써 입력하여 로봇이 영상 속 인간 작업자의 동작을 따라 하게 하는 연구 또한 존재한다. 본 논문에서는 인간 작업자의 작업과정에 대한 영상 데이터를 저장, 분류하고, 각 영상에 annotation을 추가하여 빅데이터 시스템에 저장한다. 빅데이터 시스템을 이용해 필요한 데이터를 질의하고 처리 분석하고, 판단지능을 위한 학습 데이터를 가져올 수 있다. 또한, 지속적인 판단지능 향상을 위해 학습된 모델의 결과도 빅데이터 시스템에 저장한다. 본 논문에서는 빅데이터 시스템의 설계와 저장구조 모델을 설명하며 활용성을 보인다.
Keywords
- 박범준, 조선화, 이수안, 신지운, 유혁상, 김진호
- 한국빅데이터학회지, 한국빅데이터학회
- 2019년 9월
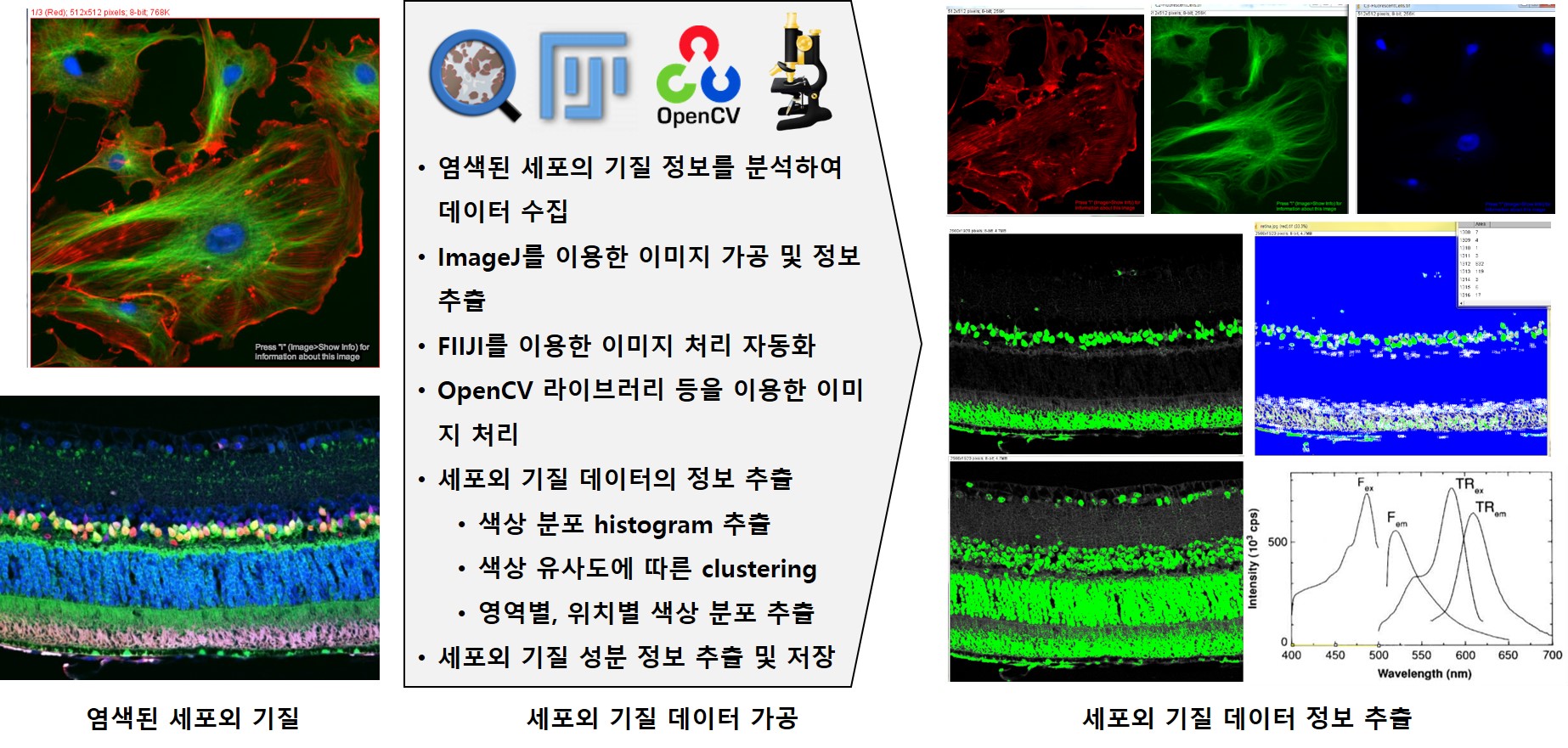
Abstract
주변 세포의 구조적, 생화학적 지지체를 제공하는 세포 외 기질은 세포의 분열과 분화 등을 좌우하는 세포 생리 조절인자이다. 바이오 분야에서는 3차원 조직공학 지지체인 스캐폴드를 제작하고, 제작한 스캐폴드에 줄기세포를 배양해 동물에 이식해 조직 재생력을 평가한다. 이는 조직 내 콜라겐과 같은 구성성분에 좌우된다. 따라서 조직 내 구성성분의 포함율 및 분포를 파악하는 것이 매우 중요한데, 이에 관한 데이터를 염색된 조직 이미지의 색상을 분석함으로써 얻어낸다. 이때 이미지 수집부터 분석까지의 과정이 적지 않은 비용이 소모되고 있고, 수집되고 분석된 데이터를 연구 기관마다 상이한 포맷으로 관리하고 있다. 따라서 데이터 통합관리 및 분석결과 검색 등이 이루어지지 않고 있다. 본 논문에서는 관련 빅데이터를 통합적으로 관리할 수 있는 데이터베이스를 구축하고, 이 연구 분야에서 중요한 분석 척도인 색상을 기준으로 검색할 수 있는 바이오 이미지 통합 관리 및 검색 시스템을 제안한다. The extracellular matrix, which provides the structural and biochemical support of surrounding cells, is a cell physiological modulator that controls cell division and differentiation. In the bio sector, the company produces Scapold, a three-dimensional support for tissue engineering, and cultivates stem cells in the produced Scapold to be transplanted into animals to assess tissue regeneration. This depends on components such as collagen in the tissue. Therefore, it is very important to identify the inclusion rate and distribution of components in the tissue, and the data are obtained by analyzing the color of the dyed tissue image. The process from image collection to analysis is costly, and the data collected and analyzed are managed in different formats by different research institutions. Therefore, data integration management and analysis results search are not being performed. In this paper, we establish a database that can manage relevant bigdata in an integrated manner, and propose a bio-image integra ed management and retrieval system that can be searched based on color, an important analytical measure in this field of study.
Keywords
바이오 세포 이미지, 세포외 기질, 이미지 분석, 시각적 검색, Bio Cell Image, extracellular matrix, image analysis, visual retrieval
- Heesang Kim, Suan Lee, SungJin Park, and Jinho Kim
- The 2nd International Workshop on Big Data Analysis for Smart Energy
- 14 Oct. 2017
Abstract
Recently, several studies attempt to process big data using Apache Spark. In addition, spammers are increasing lately, and they are exposing indiscriminate information on social networks (SNS) that users do not want. Previous relationshipbased spammer detections are not suitable for big data graph, because the detecting spammers in big data graphs requires a long computation time. Therefore, we propose an efficient spammer detection scheme based on social relations using Strongly Connected Components (SCC), which quickly finds cyclical relationships on Spark GraphX. We test our proposed spammer detection method through experiments, and it is able to find spammers in big data graph quickly.
Keywords
Spammer, Spark, Strongly Connected Components, Social Networks
- 장종원, 김희상, 김민규, 이수안, 김진호
- 한국소프트웨어종합학술대회, 한국정보과학회
- 2018년 12월
Abstract
오늘날 보안이라는 이슈가 점점 더 중요하게 여겨지고 있다. 다양한 보안 장비들로 구성된 보안관리 시스템에서는 장비마다 다른 보안 로그를 생성해내며, 그 로그들을 한데 모아 저장 및 분석할 필요가 있다. 많은 보안 장비에서 생성되는 로그의 양은 빅데이터라 할 수 있고, 기존 RDBMS를 이용하여 저장, 분석하기에는 힘든 상황이다. 따라서 본 논문에서는 대용량 로그를 저장할 수 있는 Hadoop 기반의 분산저장 데이터베이스 시스템인 HBase를 사용한 보안로그 분석시스템을 제안한다. 제안한 시스템과 기존 RDBMS와의 수행시간을 비교하였으며, 데이터가 많아질수록 HBase가 압도적으로 우수한 수행시간을 보였다.
Keywords
##
- 김민규, 이수안, 김진호, 신혜숙
- 한국소프트웨어종합학술대회, 한국정보과학회
- 2018년 12월
Abstract
빅데이터 기술은 많은 분야에서 다각적인 자료 분석이 가능하도록 활용되고 있다. 본 논문에서는 교육 분야에서 새로운 정책에 대한 효과를 평가하기 위해 빅데이터 기술을 활용하였다. 전국 중학교에서 운영되고 있는 자유학기제의 운영 실태 분석을 위하여 비정형 데이터 분석과 시각화를 통하여 주요 관심사항과 차이점에 대해서 살펴보았다. 특히 지역적으로 중요 특성과 관심 사항이 다르다는 것을 부산과 전남을 중심으로 살펴보았다. 본 연구는 교육 전문가와 함께 필요와 요구에 따라 빅데이터 분석 기술을 적용하였다는 것에 의미가 있다.
Keywords
##
- Suan Lee, Seok Kang, Jinho Kim, and Eun Jung Yu
- Cluster Computing
- 01 Feb. 2018
Abstract
A data cube is a powerful analytical tool that stores all aggregate values over a set of dimensions. It provides users with a simple and efficient means of performing complex data analysis while assisting in decision making. Since the computation time for building a data cube is very large, however, efficient methods for reducing the data cube computation time are needed. Previous works have developed various algorithms for efficiently generating data cubes using MapReduce, which is a large-scale distributed parallel processing framework. However, MapReduce incurs the overhead of disk I/Os and network traffic. To overcome these MapReduce limitations, Spark was recently proposed as a memory-based parallel/distributed processing framework. It has attracted considerable research attention owing to its high performance. In this paper, we propose two algorithms for efficiently building data cubes. The algorithms fully leverage Spark’s mechanisms and properties: Resilient Distributed Top-Down Computation (RDTDC) and Resilient Distributed Bottom-Up Computation (RDBUC). The former is an algorithm for computing the components (i.e., cuboids) of a data cube in a top-down approach; the latter is a bottom-up approach. The RDTDC algorithm has three key functions. (1) It approximates the size of the cuboid using the cardinality without additional Spark action computation to determine the size of each cuboid during top-down computation. Thus, one cuboid can be computed from the upper cuboid of a smaller size. (2) It creates an execution plan that is optimized to input the smaller sized cuboid. (3) Lastly, it uses a method of reusing the result of the already computed cuboid by top-down computation and simultaneously computes the cuboid of several dimensions. In addition, we propose the RDBUC bottom-up algorithm in Spark, which is widely used in computing Iceberg cubes to maintain only cells satisfying a certain condition of minimum support. This algorithm incorporates two primary strategies: (1) reducing the input size to compute aggregate values for a dimension combination (e.g., A, B, and C) by removing the input, which does not satisfy the Iceberg cube condition at its lower dimension combination (e.g., A and B) computed earlier. (2) We use a lazy materialization strategy that computes every combination of dimensions using only transformation operations without any action operation. It then stores them in a single action operation. To prove the efficiency of the proposed algorithms using a lazy materialization strategy by employing only one action operation, we conducted extensive experiments. We compared them to the cube() function, a built-in cube computation library of Spark SQL. The results showed that the proposed RDTDC and RDBUC algorithms outperformed Spark SQL cube().
Keywords
Distributed processing, Spark framework, Resilient distributed dataset, Data warehousing, On-line analytical processing, Multidimensional data cube, Iceberg cube
- 이수안, 이솔, 유혁상, 김진호
- 데이터베이스연구, 한국정보과학회 데이터베이스 소사이어티
- 2017년 12월 29일
Abstract
세포외 기질은 세포가 성장하고 분화하는데 필요한 생화학적 인자들과 세포를 위한 환경을 제공한다. 생체재료 분야에서는 세포외 기질의 구성 및 구조를 모방한 생체재료를 만들고, 세포를 배양하여 조직을 만들어 내는 실험이 지속되고 있다. 그러나 세포가 원하는 조직으로 잘 분화되는 3차원 지지체를 만들기 위해서는 세포외 기질에 대한 구성과 구조, 특성을 분석하고, 물리적 환경에 따른 조절 요인 등에 대한 연구가 필요하다. 본 논문에서는 형광 염색된 세포외 기질 이미지로부터 추출/가공을 통해 다양한 데이터를 저장하고 분석하는 바이오 빅데이터 시스템을 제안한다. The extracellular matrix provides the environment for cells and biochemical factors necessary for cell growth and differentiation. In the field of biomaterials, experiments have been continuing to make biomaterials that mimic the structure and structure of extracellular matrix, and use them to culture cells to produce tissues. However, it is necessary to analyze the constitution, structure, and characteristics of the extracellular matrix and to study the factors regulating the physical environment in order to produce a three-dimensional scaffold that differentiates cells into desired tissues, In this paper, we propose a bio-data system for storing and analyzing various data through extraction/processing from fluorescence-stained extracellular matrix images.

Keywords
Context awareness, Tensor data cube, MapReduce framework
- Suan Lee, Young-Seok You, Sungjin Park, and Jinho Kim
- Proceedings of the Seventh International Conference on Emerging Databases: Technologies, Applications, and Theory
- 14 Oct. 2017
Abstract
A suitable user interactive model is required to navigate efficiently in information network for users. In this paper, we have developed EEUM (Explorable and Expandable User-interactive Model) that can be used conveniently and efficiently for users in bibliographic information networks. The system shows the demonstration of efficient search, exploration, and analysis of information network using EEUM. EEUM allows users to find influential authors or papers in any research field. Also, users can see all relationships between several authors and papers at a glance. Users are able to analyze after searching and exploring (or navigating) bibliographic information networks efficiently by using EEUM.
Keywords
Information networks, Graph database, Data visualization, User-interactive model
- 이기준, 이수안, 구경아, 김진호
- 정보화 연구, 한국엔터프라이즈아키텍처학회
- 2017년 06월
Abstract
전 세계적인 경기침체로 인해 우리나라에서도 많은 문제를 겪고 있는데 이 중 청년층의 취업률 및 실업률 문제가 큰 문제로 부각되고 있다. 이를 위해 정부에서는 많은 정책을 수립하여 시행하고 있는데 이 과정에서 사용되는 기초데이터로 많이 활용되는 데이터는 고등교육기관 졸업자 취업통계 정보이다. 그러나 현재 고등교육기관 졸업자 취업통계정보는 정부차원에서의 정책 수립 및 평가에 주로 활용되고 그 내용이 취업자 수에 의한 양적 정보에 한정됨에 따라 실제 청년층의 취업률 제고에는 효과적으로 활용되고 있지 못하다는 지적이 있으며 일선 대학에서는 진로 및 취업 상세정보의 부재로 학생들의 진로 및 취업상담에 애로를 겪고 있다. 따라서 대학생의 진로 설계와 취업 지원을 위한 미래진로 빅데이터가 필요한 시점이며 이를 활용하여 청년층 실업문제를 과학적으로 접근하는 시도가 필요하다. 본 논문에서는 기존 고등교육기관 졸업자 취업통계조사를 개선하여 대학생 진로설계와 취업지원이 가능하도록 데이터를 수집하는 데이터베이스를 구축하고 정보의 수요자들이 손쉽게 본인의 진로를 결정할 수 있는 정보를 전달하는 정보시스템을 제안한다. Due to the global economic downturn, many problems have been experienced in Korea. Among them, the employment rate and the unemployment rate of the young people are becoming big problems. To this end, the government establishes and implements a number of policies. Data that are often used as basic data in this process are statistical information on employment of grad-uates of higher education institutions. However, it is pointed out that employment statistics infor-mation of graduates of higher education institutions is mainly used for policy formulation and evaluation at the government level and its content is limited to quantitative information by the number of employed persons. Therefore, there is an indication that it is not being effectively used to raise the employment rate of young people. At University, students are struggling with career and career counseling due to lack of career and employment details. It is necessary to try to approach the youth unemployment problem scientifically by utilizing the future career big data for career planning and career support of university students. In this paper, we have developed an information system that improves the employment survey of graduates of existing higher educa-tion institutions and builds a database that collects data to enable college career design and employment support, and allows information consumers to easily determine their own career path.
Keywords
빅데이터, 정보 시스템, 진로 및 취업, Big Data, Information System, Career Path, Supporting Employment
- 강석, 이수안, 김진호, 이강수
- 정보화 연구, 한국엔터프라이즈아키텍처학회
- 2017년 03월
Abstract
스마트폰의 출현으로 SNS, 위치정보, 각종 로그들을 포함에 방대한 양의 데이터가 쌓이고 있다. 이런 데이터들을 활용하여 가치있는 정보로 활용하기 위해 빅 데이터 기술에 대한 관심을 가지고 있다. 사람들이 빅 데이터 처리를 통해 나온 결과를 쉽게 알아볼 수 있는 시각화 기술에 대해서도 관심이 뜨겁다. 본 논문에서는 경영 시뮬레이션 게임에서 의사 결정을 위해서 빅 데이터 분석을 수행하였고 가공처리되서 나온 데이터들을 이용해 시각화 도구를 개발하였다. 시각화 도구에는 워드 클라우드, 단어 빈도 분석, 네트워크 그래프 분석, 군집 분석 등 다양한 시각화 도구가 있다. 이런 시각화 도구를 통해 사용자는 앞서 말한 가치 있는 정보를 확인 할 수 있다. 또한 사용자는 데이터를 필터링하거나 단어의 빈도수 또는 단어의 개수를 조절하거나 군집의 개수를 설정하여 사용자가 좀 더 쉽게 이해 할 수 있도록 시각화를 다시 할 수 있다. 이를 통해 효과적이고 탄력적인 경영과 의사 결정에 도움을 줄 수 있다. SNS with the advent of smart phones, position information, has accumulated a huge amount of data to include a variety of log. By utilizing such data, in order to take advantage of the information that is of value, we have an interest in big data technology. People are hot interest in big data processing through the you can find the results that have been briefly out of visualization technology. In this paper, we run the big data analysis for decision-making in the management simulation game, we were using the data that came out be processed to develop a visualization tool. The visualization tool, the analysis of the word cloud, word of the frequency of use, network graph analysis, cluster analysis, etc., there are a variety of visualization tools. Using such visualization tools, the user can confirm the valuable information previously described. Also, users can filter the data, or to adjust the number of words in the frequency and the word, by setting the number of congestion, the user can repeat the visualization may be more easily understood. Thus, it is possible to support effective and flexible management and decision making.
Keywords
빅 데이터, 워드 클라우드, 소셜 네트워크 분석, 군집 분석, 시뮬레이션 게임, Big Data, Word Cloud, Social Network Analysis, Clutering Analysis, Simulation Game
- Sungjin Park, Suan Lee, and Jinho Kim
- Big Data and Smart Computing (BigComp), 2017 IEEE International Conference on. IEEE
- 13-16 Feb. 2017
Abstract
A suitable user interactive model is required to navigate efficiently in information network for users. In this paper, we have developed EEUM (Explorable and Expandable User-interactive Model) that can be used conveniently and efficiently for users in bibliographic information networks. The system shows the demonstration of efficient search, exploration, and analysis of information network using EEUM. EEUM allows users to find influential authors or papers in any research field. Also, users can see all relationships between several authors and papers at a glance. Users are able to analyze after searching and exploring (or navigating) bibliographic information networks efficiently by using EEUM.
Keywords
Information networks, Graph database, Data visualization, User-interactive model
- Young Seok You, Suan Lee, and Jinho Kim
- Proceedings of the Sixth International Conference on Emerging Databases: Technologies, Applications, and Theory. ACM
- 17-19 Oct. 2016
Abstract
Typically, application or website shows the comments of people in a list format. This list means in seeing chronologically or log of recommends. However, it is difficult to grasp because of reading and knowing all countless comments of the topic at a glance. Therefore, it requires a lot of ability to grasp information at a glance via picking only the important information. In this paper, we design and develop a visualization tool that can identify a number of reviews containing comments on the movie at a glance. Review assumed to be extracted from the Amazon and IMDb that are both subjective information. The tool that we develop visualizes sentimental analysis of the review on pre-made Sentiment Dictionary with objective information of a movie. Our proposed system can search and display one or more movies. Users can determine the relationship between movies by clustering sentiment of positive/negative reviews and movie's factors. In the future, based on all the reviews on Amazon and grasp the reviews on a variety of movies and products, as well, it will be used as tools to help users of a rational choice.
Keywords
Review DAta, Sentiment Analysis, Visualization
- 이강수, 이수안, 강석, 박찬민, 김진호
- 정보화연구, 한국엔터프라이즈아키텍처학회
- 2016년 06월 30일
Abstract
스마트폰의 출현으로 SNS, 위치정보, 각종 로그들을 포함에 방대한 양의 데이터가 쌓이고 있다. 이런 데이터들을 활용하여 가치있는 정보로 활용하기 위해 빅 데이터 기술에 대한 관심을 가지고 있다. 사람들이 빅 데이터 처리를 통해 나온 결과를 쉽게 알아볼 수 있는 시각화 기술에 대해서도 관심이 뜨겁다. 본 논문에서는 경영 시뮬레이션 게임에서 의사 결정을 위해서 빅 데이터 분석을 수행하였고 가공처리되서 나온 데이터들을 이용해 시각화 도구를 개발하였다. 시각화 도구에는 워드 클라우드, 단어 빈도 분석, 네트워크 그래프 분석, 군집 분석 등 다양한 시각화 도구가 있다. 이런 시각화 도구를 통해 사용자는 앞서 말한 가치 있는 정보를 확인 할 수 있다. 또한 사용자는 데이터를 필터링하거나 단어의 빈도수 또는 단어의 개수를 조절하거나 군집의 개수를 설정하여 사용자가 좀 더 쉽게 이해 할 수 있도록 시각화를 다시 할 수 있다. 이를 통해 효과적이고 탄력적인 경영과 의사 결정에 도움을 줄 수 있다. SNS with the advent of smart phones, position information, has accumulated a huge amount of data to include a variety of log. By utilizing such data, in order to take advantage of the information that is of value, we have an interest in big data technology. People are hot interest in big data processing through the you can find the results that have been briefly out of visualization technology. In this paper, we run the big data analysis for decision-making in the management simulation game, we were using the data that came out be processed to develop a visualization tool. The visualization tool, the analysis of the word cloud, word of the frequency of use, network graph analysis, cluster analysis, etc., there are a variety of visualization tools. Using such visualization tools, the user can confirm the valuable information previously described. Also, users can filter the data, or to adjust the number of words in the frequency and the word, by setting the number of congestion, the user can repeat the visualization may be more easily understood. Thus, it is possible to support effective and flexible management and decision making.
Keywords
물류 데이터, 데이터 크롤러, 빅 데이터 분석, 텍스트 시각화, Logistics Data, Data Crawler, Big Data Analysis, Text Visualization
- 이수안, 최재용, 강상원, 이기준, 한명훈, 김진호
- 정보화연구, 한국엔터프라이즈아키텍처학회
- 2016년 03월 30일
Abstract
많은 공공기관과 기업들이 전자문서를 이용하고 있으며 자체적으로 전자문서관리시스템을 운영하고 있다. 그러나 최근 전자문서의 범위는 지식, 정보, 콘텐츠를 포함하는 것으로 확대되어가고 있다. 또한 사용자들은 전자문서의 공유 및 협업에 대한 요구가 증가되는 한편, 모바일과 사물인터넷 등으로 데이터의 양은 급증하고 있다. 이러한 대규모의 데이터를 처리하며 IT 자원을 효율적으로 관리해주는 클라우드 컴퓨팅이 활성화되고 있다. 그리하여 본 논문에서는 클라우드 환경에서 자동화 기술을 통해 IT 자원을 상황에 맞게 조절하고, 시스템의 확장 및 축소가 가능한 전자문서관리에 대해서 연구하였다. 또한 클라우드 환경에서 스토리지 관리 기법과 전자문서의 체계적인 복제본 관리기술 등에 대해서 제안하였다. Many public institutions and companies have been utilizing a lot of electronic documents and have been operating electronic document management systems on their own. However, the scope of the recent electronic documents is becoming enlarged to include knowledge, information, contents, etc. In addition, users have an increasing demand for sharing and collaborating the electronic documents. With the recent advance of mobile and Internet of Things(IoT) technologies, furthermore, the size of data are increasing very rapidly and tremendously. In order to manage a huge amount of data, cloud computing technology has been raving up more and more, which can handle IT resources efficiently. Thus, we have studied the electronic document management system which is possible to expand and to collapse to suit users' needs and IT resources automatically in cloud environments. In addition, we propose an efficient storage management system and a systematic replica management technology of electronic documents in cloud environments.
Keywords
전자문서, 전사콘텐츠관리(ECM), 전자문서관리시스템(EDMS), 클라우드 컴퓨팅, 클라우드 스토리지 서비스, Electronic Document, Enterprise Contents Management, Electronic Document Management System, Cloud Computing, Cloud Storage Service
- Suan Lee, and Jinho Kim
- Big Data and Smart Computing (BigComp), 2016 International Conference on. IEEE
- 18-20 Jan. 2016
Abstract
This paper presents the performance evaluation of MRDataCube which we have previously proposed as an efficient algorithm for data cube computation with data reduction using MapReduce framework. We performed a large number of analyses and experiments to evaluate the MRDataCube algorithm in the MapReduce framework. In this paper, we compared it to simple MR-based data cube computation algorithms, e.g., MRNaive, MR2D as well as algorithms converted into MR paradigms from conventional ROLAP (relational OLAP) data cube algorithms, e.g., MRGBLP and MRPipeSort. From the experimental results, we observe that the MRDataCube algorithm outperforms the other algorithms in comparison tests by increasing the number of tuples and/or dimensions.
Keywords
Data Warehouse, Data Cube, OLAP, MapReduce, Hadoop, Multidimensional Analysis, Distributed Parallel Processing
- Suan Lee, Jinho Kim, Yang-Sae Moon, and Wookey Lee
- Transactions on Large-Scale Data-and Knowledge-Centered Systems XXI
- 17 July 2015
Abstract
Data cube is an essential part of OLAP(On-Line Analytical Processing) to support efficiently multidimensional analysis for a large size of data. The computation of data cube takes much time, because a data cube with d dimensions consists of 2 d (i.e., exponential order of d) cuboids. To build ROLAP (Relational OLAP) data cubes efficiently, many algorithms (e.g., GBLP, PipeSort, PipeHash, BUC, etc.) have been developed, which share sort cost and input data scan and/or reduce data computation time. Several parallel processing algorithms have been also proposed. On the other hand, MapReduce is recently emerging for the framework processing huge volume of data like web-scale data in a distributed/parallel manner by using a large number of computers (e.g., several hundred or thousands). In the MapReduce framework, the degree of parallel processing is more important to reduce total execution time than elaborate strategies like short-share and computation-reduction which existing ROLAP algorithms use. In this paper, we propose two distributed parallel processing algorithms. The first algorithm called MRLevel, which takes advantages of the MapReduce framework. The second algorithm called MRPipeLevel, which is based on the existing PipeSort algorithm which is one of the most efficient ones for top-down cube computation. (Top-down approach is more effective to handle big data, compared to others such as bottom-up and special data structures which are dependent on main-memory size.) The proposed MRLevel algorithm tries to parallelize cube computation and to reduce the number of data scan by level at the same time. The MRPipeLevel algorithm is based on the advantages of the MRLevel and to reduce the number of data scan by pipelining at the same time. We implemented and evaluated the performance of this algorithm under the MapReduce framework. Through the experiments, we also identify the factors for performance enhancement in MapReduce to process very huge data.
Keywords
Data cube, ROLAP, MapReduce, Hadoop, Distributed parallel computing
- Suan Lee, Sunhwa Jo, Ji-Seop Won, Jinho Kim, and Yang-Sae Moon
- Applied Mathematics & Information Sciences
- 1 May 2015
Abstract
Recently new mobile devices such as cellular phones, smartphones, and digital cameras are popularly used to take photos. By virtue of these convenient instruments, we can take many photos easily, but we suffer from the difficulty of managing and searching photos due to their large volume. This paper develops a mobile application software, called Photo Cube, which automatically extracts various metadata for photos (e.g., date/time, address, place name, weather, personal event, etc.) by taking advantage of sensors and programming functions embedded in mobile smartphones like Android phones or iPhones. To avoid heavy network traffic and high processing overhead, it clusters photos into a set of clusters hierarchically by GPSs and it extracts the metadata for each centroid photo of clusters automatically. Then it constructs and stores the hierarchies of clusters based on the date/time, and address within the extracted metadata as well as the other metadata into photo database tables in the flash memory of smartphones. Furthermore, the system builds a multidimensional cube view for the photo database, which is popularly used in OLAP(On-Line Analytical Processing) applications and it facilitates the top-down browsing of photos over several dimensions such as date/time, address, etc. In addition to the hierarchical browsing, it provides users with keyword search function in order to find photos over every metadata of the photo database in a user-friendly manner. With these convenient features of the Photo Cube, therefore, users will be able to manage and search a large number of photos easily, without inputting any additional information but with clicking simply the shutter in a camera.
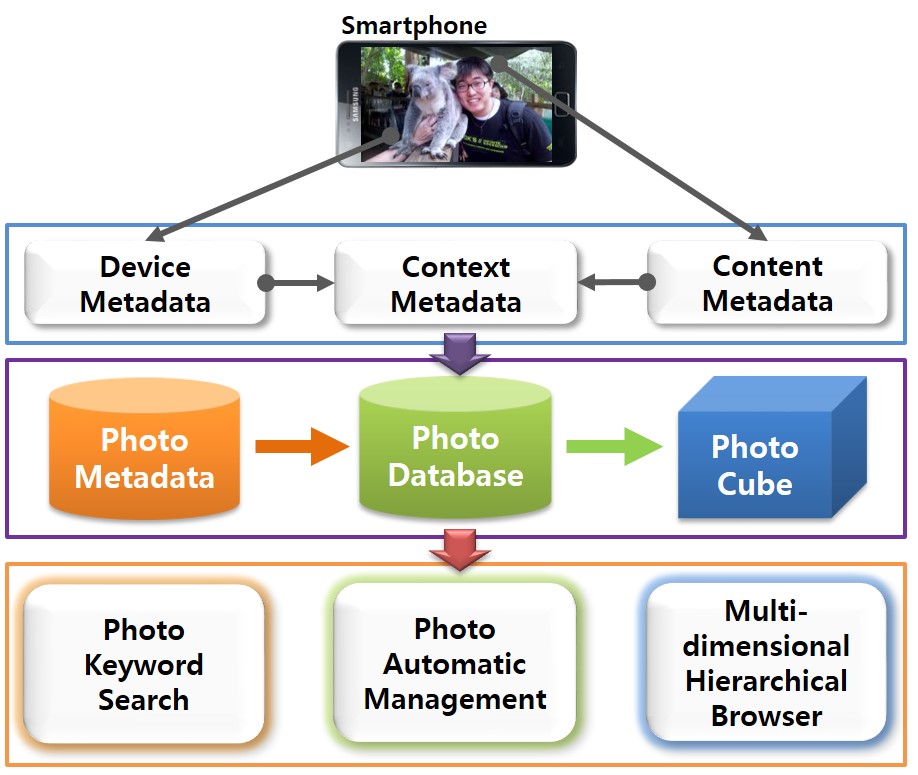

Keywords
photo metadata, photo annotation, clustered databases, multidimensional data cube, OLAP, hierarchical clustering, keyword search, multidimensional hierarchical browsing, mobile application, smartphones
- Jaeyong Choi, Suan Lee, Sangwon Kang, and Jinho Kim
- Big Data and Smart Computing (BigComp), 2015 International Conference on. IEEE
- 9-11 Feb. 2015
Abstract
In recent years, the amount of data produced by mobile devices and the Internet has increased rapidly. To facilitate the storage of such a large amount of data, open-source-based cloud storage services have also increased. However, most of administration tools which are specialized in managing open-source-based storage services have shortcomings such as lack of sufficient features and difficulty in operation. In this paper, we designed and implemented a GUI(Graphic User Interface) tool for managing OpenStack Swift, an open-source cloud storage services, to resolve these shortcomings. In addition, this tool incorporates a feature for the power management of computers/nodes within a cloud storage cluster to improve energy efficiency.
Keywords
graphic monitoring tool, cloud service, cloud storage system, data center, OpenStack, Swift
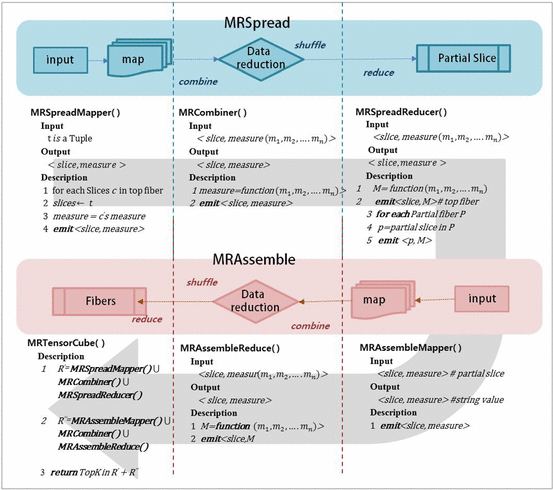
- Suan Lee, Sunhwa Jo, and Jinho Kim
- Big Data and Smart Computing (BigComp), 2015 International Conference on. IEEE
- 9-11 Feb. 2015
Abstract
Data cube is used as an OLAP (On-Line Analytical Processing) model to implement multidimensional analyses in many fields of application. Computing a data cube requires a long sequence of basic operations and storage costs. Exponentially accumulating amounts of data have reached a magnitude that overwhelms the processing capacities of single computers. In this paper, we implement a large-scale data cube computation based on distributed parallel computing using the MapReduce (MR) computational framework. For this purpose, we developed a new algorithm, MRDataCube, which incorporates the MR mechanism into data cube computations such that effective data cube computations are enabled even when using the same computing resources. The proposed MRDataCube consists of two-level MR phases, namely, MRSpread and MRAssemble. The main feature of this algorithm is a continuous data reduction through the combination of partial cuboids and partial cells that are emitted when the computation undergoes these two phases. From the experimental results we revealed that MRDataCube outperforms all other algorithms.
Keywords
distributed parallel algorithm, cube, OLAP, multi-dimensional analysis, data cube computation, MapReduce, Hadoop
- Suan Lee, Namsoo Kim, and Jinho Kim
- Big Data and Cloud Computing (BdCloud), 2014 IEEE Fourth International Conference on. IEEE
- 3-5 Dec. 2014
Abstract
Recently, unstructured data like texts, documents, or SNS messages has been increasingly being used in many applications, rather than structured data consisting of simple numbers or characters. Thus it becomes more important to analysis unstructured text data to extract valuable information for usres decision making. Like OLAP (On-Line Analytical Processing) analysis over structured data, Multi-dimensional analysis for these unstructured data is popularly being required. To facilitate these analysis requirements on the unstructured data, a text cube model on multi-dimensional text database has been proposed. In this paper, we extended the existing text cube model to incorporate TF-IDF (Term Frequency Inverse Document Frequrency) and LM (Language Model) as measurements. Because the proposed text cube model utilizes new measurements which are more popular in information retrieval systems, it is more efficient and effective to analysis text databases. Through experiments, we revealed that the performance and the effectiveness of the proposed text cube outperform the existing one.
Keywords
language model, OLAP, Multi-dimensional analysis, text cube, data cube, text databases, information retrieval, TF-IDF
- Wookey Lee, Suan Lee, and Jinho Kim
- International Conference on Database Systems for Advanced Applications. Springer
- 11 July 2014
Abstract
When information is searched via internet, a browser indicates information about web pages on a single window, but the existing browser shows only fragments of page information to web surfing users who visit several sites at once and in turn causes insufficiency and inconvenience to the users. Rich Internet Application techniques, which are web application techniques for the simple and easy operation and diverse and dynamic screen composition, have received a lot of attention as a next-generation UI technique emphasizing on users’ convenience. In this dissertation, a two-dimensional and sequential advanced search is realized with the use of dynamic UI so users can save and employ the customized search information for further web search. Also, the search structure has been designed with the use of user-oriented keyword preference to have more customizes search results than the existing web search. Furthermore, this paper has proven a decrease in the number of searched pages by employing the customized search administrator using RIA techniques. Thus, it could be concluded that the customized search administrator supports users of the more efficient and flexible customize web search.
Keywords
Web browser, UI technique, Web search, Rich internet application technique, Customized search
- 김남수, 이수안, 조선화, 김진호
- 정보화연구, 한국엔터프라이즈아키텍처학회
- 2014년 03월 30일
Abstract
웹의 발달로 텍스트 등으로 이루어진 비정형 데이터의 활용에 대한 관심이 높아지고 있다. 웹 상에서 사용자들이 작성한 대부분의 비정형 데이터는 사용자의 주관이 담겨져있어 이를 적절히 분석 할 경우 사용자의 취향이나 주관적인 관점 등의 아주 유용한 정보를 얻을 수 있다. 이 논문에서는 이러한 비정형 텍스트 문서를 다양한 차원으로 분석하기 하는데 OLAP(온라인 분석 처리)의 다차원 데 이터 큐브 기술을 활용한다. 다차원 데이터 큐브는 간단한 문자나 숫자 형태의 정형적인 데이터에 대 해 다차원 분석하는데 널리 사용되었지만, 텍스트 문장으로 이루어진 비정형 데이터에 대해서는 활용 되지 않았다. 이러한 텍스트 데이터베이스에 포함된 정보를 다차원으로 분석하기 위한 방법으로 텍스 트큐브 모델이 최근에 제안되었는데, 이 텍스트 큐브는 정보 검색에서 널리 사용하는 용어 빈도수 (Term Frequency)와 역 인덱스(Inverted Index)를 측정값으로 이용하여 텍스트 데이터베이스에 대 한 다차원 분석을 지원한다. 이 논문에서는 이러한 다차원 텍스트 큐브를 활용하여 실제 서비스되고 있는 호텔 정보 공유 사이트의 리뷰 데이터 분석에 활용하였다. 이를 위해 호텔 리뷰 데이터에 대한 다차원 텍스트 큐브를 생성하였으며, 이를 이용하여 다차원 키워드 검색 기능을 제공하여 사용자 중 심의 의미있는 정보 검색이 가능한 시스템을 설계 및 구현하였다. 또한, 본 논문에서 제안하는 시스템 에 대해 다양한 실험을 수행하였으며 이를 통해 제안된 시스템의 실효성을 검증하였다. As the advance of WWW, unstructured data including texts are taking users' interests more and more. These unstructured data created by WWW users represent users' subjective opinions thus we can get very useful information such as users' personal tastes or perspectives from them if we analyze appropriately. In this paper, we provide various analysis efficiently for unstructured text documents by taking advantage of OLAP (On-Line Analytical Processing) multidimen-sional cube technology. OLAP cubes have been widely used for the multidimensional analysis for structured data such as simple alphabetic and numberic data but they didn't have used for unstructured data consisting of long texts. In order to provide multidimensional analysis for unstructured text data, however, Text Cube model has been proposed precently. It incorporates term frequency and inverted index as measurements to search and analyze text databases which play key roles in information retrieval. The primary goal of this paper is to apply this text cube model to a real data set from in an Internet site sharing hotel information and to provide multidimensional analysis for users' reviews on hotels written in texts. To achieve this goal, we first build text cubes for the hotel review data. By using the text cubes, we design and implement the system which provides multidimensional keyword search features to search and to analyze review texts on various dimensions. This system will be able to help users to get valuable guest-subjective summary information easily. Furthermore, this paper evaluats the proposed systems through various experiments and it reveals the effectiveness of the system.
Keywords
다차원 텍스트 데이터베이스, 텍스트 큐브, 온라인 다차원 분석, 사용자 리뷰 분석, 키워드 검색 Multi-dimensional Text Databases, Text Cubes, On-Line Analytical Processing (OLAP), Usres' review analysis, keyword search
- Suan Lee, Jinho Kim, Jiseop Won, Namsoo Kim, Johyeon Kang, and Sunhwa Jo
- Cloud and Green Computing (CGC), 2013 Third International Conference on. IEEE
- 30 Sept.-2 Oct. 2013
Abstract
Nowadays, it is popular for users to take photos through mobile devices like smartphones. In order to help users to search lots of photos within their smartphones easily, this paper develops a mobile application software system supporting a keyword search feature over photos just like searching web pages in the Internet. When a user takes a photo, the system extracts its meta-data of date/time and GPS as well as its various annotations automatically (e.g., mailing address, place names, event names, weather, etc.). Based on the annotations, we implemented a keyword search function over photos in smartphones. With this system, users can easily search photos with keyword conditions, even though they don't give any additional information.
Keywords
Keyword Search Over Databases, Mobile Application, Smartphone, Image Retrieval, Image Annotation, Keyword Search
- Suan Lee, Jaenam Choi, Won Seo, Younghun Kim, Joonho Park, Kwangik Seo, and Nacwoo Kim
- Proceedings of the Fifth International Conference on Emerging Databases: Technologies, Applications, and Theory. ACM
- 19-21 Aug. 2013
Abstract
In the emerging big data era, the needs of the real-time processing are rising. The data explosion changes the point of view of the data processing, from "store first, process later" to "process first, selectively store later". Real-time event processing is based on "process first, selectively store later" model, also known as active data processing. In this paper we introduce the commercial event processing engine, ALTIBASE CEP. It is an event processing engine which adopts active data processing model. We propose a use-case of fire alarm system, which detects abnormal situations and alarms them to users. ALTIBASE CEP is expected to take a core role in diverse sectors for the real-time event processing.
Keywords
complex event processing, embedded, real-time, in-memory, CEP
- 이수안, 김진호
- 전자공학회논문지, 대한전자공학회
- 2012년 09월 30일
Abstract
최근 많은 응용 분야에서 대규모 데이터에 대해 온라인 다차원 분석(OLAP)을 사용하고 있다. 다차원 데이터 큐브는 OLAP 분석에서 핵심 도구로 여긴다. 본 논문에서는 맵리듀스 분산 병렬 처리를 이용하여 효율적으로 데이터 큐브를 계산하는 방법을 연구하고자 한다. 이를 위해, 맵리듀스 프레임워크에서 데이터 큐브 계산 방법으로 잘 알려진 PipeSort 알고리즘을 구현하는 효율적인 방법에 대해서 살펴본다. PipeSort는 데이터 큐브의 한 큐보이드에서 동일한 정렬 순서를 갖는 여러 큐보이드를 한 파이프라인으로 한꺼번에 계산하는 효율적인 방식이다. 이 논문에서는 맵리듀스 프레임워크에서 PipeSort의 파이프라인을 구현한 네 가지 방법을 20대의 서버에서 수행하였다. 실험 결과를 보면, 고차원 데이터에 대해서는 PipeMap-NoReduce 알고리즘이 우수한 성능을 보였으며, 저차원 데이터에 대해서는 Post-Pipe 알고리즘이 더 우수함을 보였다. Recently, many applications perform OLAP(On-Line Analytical Processing) over a very large volume of data. Multidimensional data cube is regarded as a core tool in OLAP analysis. This paper focuses on the method how to efficiently compute data cubes in parallel by using a popular parallel processing tool, MapReduce. We investigate efficient ways to implement PipeSort algorithm, a well-known data cube computation method, on the MapReduce framework. The PipeSort executes several (descendant) cuboids at the same time as a pipeline by scanning one (ancestor) cuboid once, which have the same sorting order. This paper proposed four ways implementing the pipeline of the PipeSort on the MapReduce framework which runs across 20 servers. Our experiments show that PipeMap-NoReduce algorithm outperforms the rest algorithms for high-dimensional data. On the contrary, Post-Pipe stands out above the others for low-dimensional data.
Keywords
multidimensional Data Cube, MapReduce, Distributed Parallel Computing, PipeSort
- 최재용, 원지섭, 이수안, 김진호
- 정보과학회논문지, 한국정보과학회
- 2012년 09월 30일
Abstract
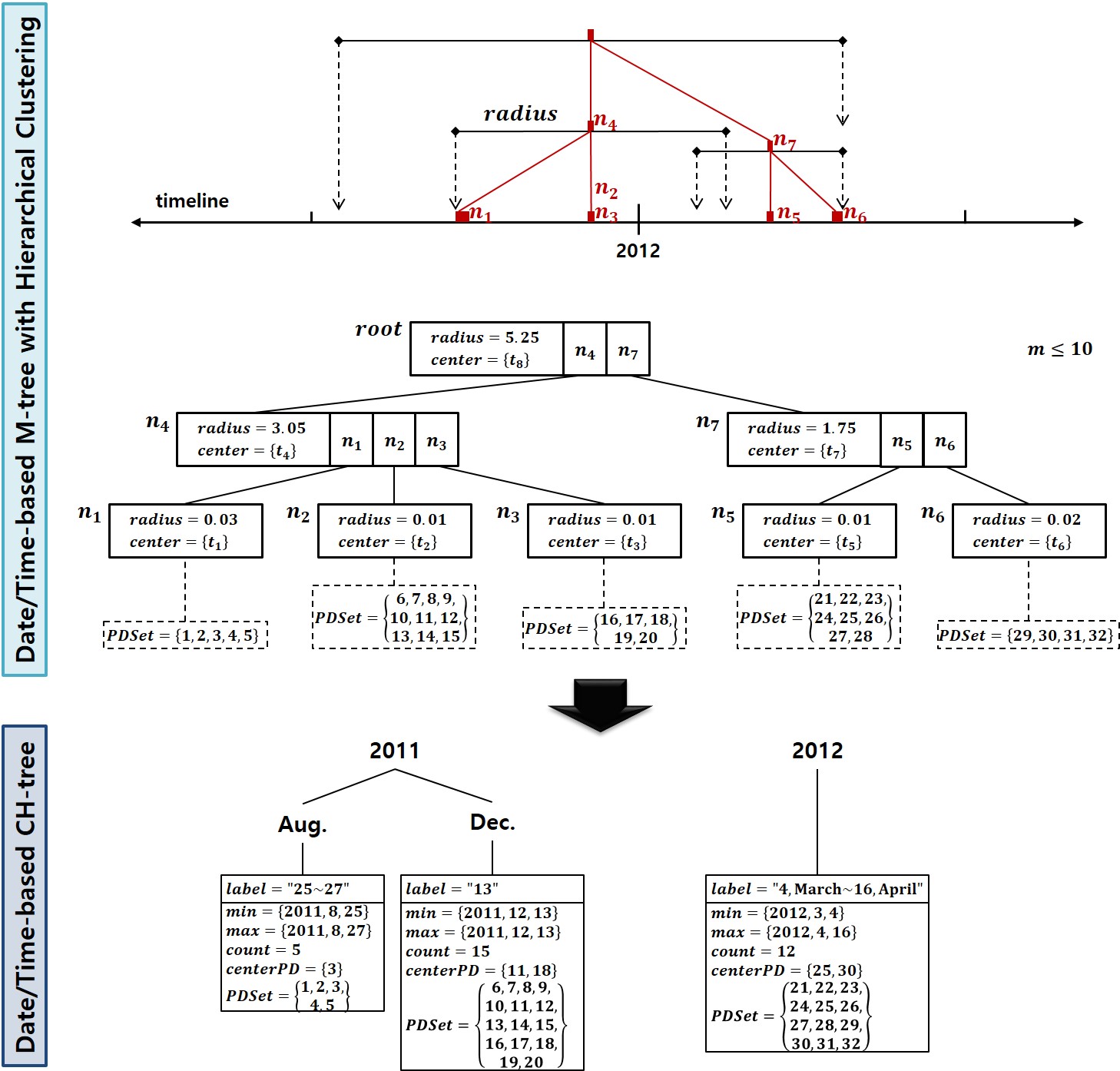
최근 스마트폰의 보급이 확산되고, 대중화됨에 따라 기존의 많은 모바일 기기들을 대체하고 있다. 많은 사용자들은 스마트폰을 이용한 사진 촬영을 취미뿐만 아니라 일상생활의 한 부분으로 많이 이용하고 있다. 하지만, PC에 비해 제한된 처리 능력과 디스플레이 크기를 가진 스마트폰에서 사진의 양이 증가함에 따라 단일 분류 기준으로는 관리 및 탐색에 어려움이 있다. 본 논문에서는 스마트폰에서 날짜/시간, GPS 정보를 추출한 뒤, 계층 모델을 생성하고, 계층 모델에 따라 사진 분류를 통해 효과적인 계층적 사진 탐색을 제공한다. 본 논문에서 제안한 시스템은 (1) 사용자 지정 가상 계층에 따른 사진 탐색, (2) 계층 트리 노드 병합을 이용한 사진 탐색, 그리고 (3) 균형 계층 트리를 이용한 사진 탐색 기법을 이용하여 사진 탐색의 편리함과 효율성을 극대화 하였으며, 구글 안드로이드 기반의 스마트폰에서 계층적 사진 탐색기를 설계 및 개발하였다. Recently smart phones are replacing a number of existing mobile devices while gaining wide popularity. Taking pictures with smart phones became a big part of our daily lives as well as hobbies. However, smart phones have limited processing capabilities and display size compared to a PC. Therefore, it is hard to manage and explore photos in a single category basis when the number of photos in a phone increase. This paper provides an effective hierarchical photo exploring system. As generating a hierarchical model by extracting date/time and GPS data from smartphones, this system offers us with an efficient way to explore photos. This photo exploring system features (1) using user customizable virtual hierarchy (2) using hierarchical tree nodes merge (3) maximizing efficiency and convenience by using balanced hierarchy tree. It was designed and developed using a Google Android smart phone.
Keywords
사진 메타데이터, 사진 관리, 사진 검색, 계층 모델, 스마트폰 Photo Metadata, Photo Management, Photo Search, Hierarchy Model, Smartphone
- Suan Lee, Jinho Kim, Yang-Sae Moon, and Wookey Lee
- Data Warehousing and Knowledge Discovery: 14th International Conference, DaWaK 2012
- 3-6 Sept. 2012
Abstract
The computation of multidimensional OLAP(On-Line Analytical Processing) data cube takes much time, because a data cube with D dimensions consists of 2 D cuboids. To build ROLAP(Relational OLAP) data cubes efficiently, existing algorithms (e.g., GBLP, PipeSort, PipeHash, BUC, etc) use several strategies sharing sort cost and input data scan, reducing data computation, and utilizing parallel processing techniques. On the other hand, MapReduce is recently emerging for the framework processing a huge volume of data like web-scale data in a distributed/parallel manner by using a large number of computers (e.g., several hundred or thousands). In the MapReduce framework, the degree of parallel processing is more important to reduce total execution time than elaborate strategies. In this paper, we propose a distributed parallel processing algorithm, called MRPipeLevel, which takes advantage of the MapReduce framework. It is based on the existing PipeSort algorithm which is one of the most efficient ones for top-down cube computation. The proposed MRPipeLevel algorithm parallelizes cube computation and reduces the number of data scan by pipelining at the same time. We implemented and evaluated the proposed algorithm under the MapReduce framework. Through the experiments, we also identify factors for performance enhancement in MapReduce to process very huge data.
Keywords
Data Cube, ROLAP, MapReduce, Hadoop, Distributed Parallel Computing
- 최재용, 이수안, 김진호
- 한국컴퓨터종합학술대회, 한국정보과학회
- 2012년 06월
Abstract
본 논문에서는 얼굴 인식 기술과 SNS 정보를 이용하여 사람의 얼굴을 기준으로 사진들을 효과적으로 분류하고 검색할 수 있는 시스템을 개발하였다. 얼굴 인식 기술을 이용하여 촬영된 사진의 분석을 통해 얼굴로부터 나이, 성별, 안경 착용 유무, 웃는 얼굴 판단 등의 의미적인 정보를 추출한다. 또한, 얼굴 인식을 통해 얻은 SNS 정보에서는 이름, 생일, 학력, 직업, 고향, 관심 분야, 종교 등의 개인적인 정보를 추출할 수 있다. 추출한 정보를 이용한 효과적인 사진 분류 및 검색을 통해 사용자의 편의를 극대화하였다. 본 논문에서는 구글 안드로이드 기반의 스마트폰에서 제안한 사진 자동 분류 및 검색 시스템을 구현하였다.
- 이수안, 김진호
- 정보화연구, 한국엔터프라이즈아키텍처학회
- 2012년 03월 30일
Abstract
최근 데이터의 폭발적인 증가로 인해 대규모 데이터의 분석에 대한 요구를 충족할 수 있는 방법들이 계속 연구되고 있다. 본 논문에서는 맵리듀스를 이용한 분산 병렬 처리를 통해 대규모 데이터큐브의 효율적인 계산이 가능한 MRIterativeBUC 알고리즘을 제안하였다. MRIterativeBUC 알고리즘은 기존의 BUC 알고리즘을 맵리듀스의 반복적 단계에 따른 효율적인 동작이 가능하도록 개발되었고, 기존의 대규모 데이터 큐브 계산에 따른 문제인 데이터 크기와 저장 및 처리 능력의 한계를 해결하였다. 또한, 분석자의 관심 부분에 대해서만 계산하는 빙산 큐브 개념의 도입과 파티셔닝, 정렬과 같은 큐브 계산을 분산 병렬 처리하는 방법 등의 장점들을 통해 데이터 방출량을 줄여서 네트워크 부하를 줄이고, 각 노드의 처리량을 줄이며, 궁극적으로 전체 큐브 계산 비용을 줄일 수 있다. 본 연구결과는 맵리듀스를 이용한 데이터 큐브 계산에 대해서 상향식 처리와 반복적 알고리즘을 통해 다양한 확장이 가능하며, 여러 응용 분야에서 활용이 가능할 것으로 예상된다. Due to the recent data explosion, methods which can meet the requirement of large data analysis has been studying. This paper proposes MRIterativeBUC algorithm which enables efficient computation of large data cube by distributed parallel processing with MapReduce framework. MRIterativeBUC algorithm is developed for efficient iterative operation of the BUC method with MapReduce, and overcomes the limitations about the storage size and processing ability caused by large data cube computation. It employs the idea from the iceberg cube which computes only the interesting aspect of analysts and the distributed parallel process of cube computation by partitioning and sorting. Thus, it reduces data emission so that it can reduce network overload, processing amount on each node, and eventually the cube computation cost. The bottom-up cube computation and iterative algorithm using MapReduce, proposed in this paper, can be expanded in various way, and will make full use of many applications.
Keywords
데이터 큐브, BUC 알고리즘, 맵리듀스, 분산 병렬 컴퓨팅 Data Cube, BUC Algorithm, MapReduce, Distributed Parallel Computing
- Jinho Kim, Suan Lee, Ji-Seop Won, and Yang-Sae Moon
- Dependable, Autonomic and Secure Computing (DASC), 2011 IEEE Ninth International Conference on. IEEE
- 12-14 Dec. 2011
Abstract
Recently new mobile devices such as cellular phones, smart phones, and digital cameras are popularly used to take photos. By the virtue of these convenient instruments, we can take many photos easily, but we suffer from the difficulty of managing and searching photos due to their large volume. This paper develops a mobile application software, called Photo Cube, which automatically extracts various metadata for photos (e.g., date/time, place/address, weather, personal event, etc.) by taking advantage of sensors and networking functions embedded in mobile smart phones like Android phones or iPhones. The metadata can be used to manage and to search photos. Using this Photo Cube, users will be able to classify, store, manage, and search a large number of photos easily, without specifying any information but just clicking the shutter in a camera. The Photo Cube system was implemented on smart phones using Google's Android.
Keywords
multidimensional search, photo metadata, photo annotation, image databases, mobile application, smartphones, text search
- 이수안, 원지섭, 최재용, 김진호
- 가을 학술발표논문집, 한국정보과학회
- 2011년 11월
Abstract
본 논문에서는 모바일에서 수천, 수만장의 사진을 효과적으로 관리하기 위한 사진 탐색기에서 대해서 제안하였다. 대부분의 사람들은 개인적인 분류 기준에 따라서 사진을 분류 및 관리한다. 하지만 사진의 양이 많아짐에 따라 기존의 단일 분류 기준으로는 관리 및 탐색의 어려움이 있다. 본 논문에서는 촬영된 사진에서 날짜/시간, 주소를 자동으로 추출하고, 추출된 정보의 계층 구조에 따라 사진을 효과적으로 자동 분류한다. 또한, 계층 모델의 구조에 따라 사용자가 언제든지 변경가능한 가상 계층 디렉토리 기능을 제공하고, 동적 계층 탐색 기능을 제공하여 사용자가 쉽고 빠르게 사진을 탐색할 수 있다. 사용자는 사진만 촬영하면, 편리하게 사진을 계층 분류 및 관리할 수 있는 기능을 사용할 수 있다. 본 논문에서는 구글 안드로이드 기반의 스마트 폰에서 제안한 계층적 사진 탐색기를 구현하였다.
- 최미정, 함효식, 이수안
- 한국통신학회 종합 학술 발표회 논문집 (추계)
- 2011년 11월
Abstract
최근 기술의 발달로 기계간의 통신을 지칭하는 M2M 개념이 등장하였고, 모바일 기기의 보급 확산으로 편의성을 더하고, 스마트한 세상을 열어가고 있다. 현재 스마트폰, 태블릿 PC 등 많은 모바일 장비들이 자체 내에 센서를 내장하고 있으며 다양한 센싱 정보를 제공하고 있다.본 논문에서는 M2M 모바일 장비에 탑재된 센서의 데이터를 효율적으로 관리하는 에이전트를 설계한다. 모바일 센서 관리 에이전트는 센서 데이터의 효율적인 저장 및 검색을 위해 정제 및 축소 기법을 사용하고, 센서 데이터의 통신 오버헤드를 줄이기 위한 통지 기법을 제안한다.
- Suan Lee, Yang-Sae Moon, and Jinho Kim
- Proceedings of 3rd International Conference on Emerging Databases
- 25-27 Aug. 2011
Abstract
Data cube has been studied for efficient analysis of large scale multidimensional data, and it has been used for multidimensional analysis and decision-making in various applications. Recently, MapReduce framework has been developed and utilized for distributed parallel processing of large scale data efficiently. This paper proposes the MRTDC algorithm to compute large scale multidimensional data cubes in top-down fashion by using the MapReduce framework. We reveal through experimental results that the MRTDC algorithm is quite efficiently operated within a little processing time as it reuses resulting data and reduces file I/O.
Keywords
multidimensional database, data warehouse, data cube, mapreduce
- 강상원, 최재용, 이수안, 김진호
- 학술 심포지움 논문집, 한국정보과학회
- 2011년 6월
Abstract
클라우드 컴퓨팅은 차세대 인터넷 컴퓨팅 패러다임으로 등장하여 뛰어난 접근성, 확장성, 비용절감 등의 효과로 인해 인터넷 기업들을 중심으로 빠르게 도입되고 있다. 또한 스마트폰, 넷북 등 각종 모바일 기기의 진화와 맞물려 클라우드 컴퓨팅 서비스는 IT 트랜드의 중심으로 자리잡고 있다. 이에 본 논문에서는 클라우드 컴퓨팅에 대한 개념 및 동향과 함께 2014인천아시아경기 대회정보시스템의 분석 사례를 들어 클라우드 컴퓨팅의 효율성과 비용절감 효과에 대해서 살펴본다.
- Suan Lee, Yang-Sae Moon, and Jinho Kim
- Proceedings of 2nd International Conference on Emerging Databases
- 30-31 Aug. 2010
Abstract
Data cubes enable us to efficiently analyze a large volume of data, but the computation of data cubes causes the severe processing time and space overhead. Iceberg cubes alleviate the overhead of data cube computation by performing the focused analysis on a small part of data cubes. However, iceberg cubes still require a lot of CPU and memory resources. To solve this problem, we adopt the MapReduce framework in computing iceberg cubes. We propose two MapReduce-based algorithms, MR-Naïve and MR-BUC, which efficiently compute iceberg cubes in a fully distributed and parallel manner. Experimental results show that, compared with the traditional algorithm, our MapReduce-based algorithms improve the computation performance by an order of magnitude.
Keywords
OLAP, data cubes, iceberg cubes, MapReduce, cloud computing
- 이수안, 최미정, 김진호
- 학술 심포지움 논문집, 한국정보과학회
- 2010년 6월
Abstract
최근 거대하고 다양한 네트워크의 관리를 위해 네트워크 관리 시스템을 많이 사용하고 있다. 하지만 단순히 네트워크에 대한 관리 정보 뿐만 아니라 프로토콜 별 트래픽 분석이나 QoS 등에 필요한 다차원 정보가 필요하다. 본 논문에서는 MIB 기반의 네트워크 관리 시스템의 효율적인 다차원 분석을 위해 데이터 웨어하우스를 설계하였다. 이러한 설계를 기반으로 기존 정보로는 분석하기 어려운 많은 요구 사항에 대해서 질의할 수 있으며, 네트워크 설계나 트래픽, QoS 등에 이용이 가능하다.
- 이수안, 김진호, 문양세
- 학술 심포지움 논문집, 한국정보과학회
- 2010년 6월
Abstract
클라우드 컴퓨팅은 새로운 IT 기술의 중요한 패러다임으로 인터넷 기업들을 중심으로 적용되고 있으며, 관련된 연구 및 기술 개발 등이 활발히 이루어지고 있다. 지속적인 데이터 증가로 대규모 데이터를 체계화된 정보로 가공 및 저장 관리에 대한 요구가 확산되고 있다. 본 논문에서는 클라우드 컴퓨팅에 대한 기술과 데이터 웨어하우스를 위한 기술 동향, 그리고 클라우드 컴퓨팅 환경에서 데이터 웨어하우스 연구와 서비스 등을 통해 차세대 데이터 웨어하우스의 전망에 대해서 살펴본다.
- 이수안, 김진호, 문양세, 노웅기
- 한국컴퓨터종합학술대회, 한국정보과학회
- 2010년 6월
Abstract
대용량 데이터의 효율적 분석을 위해 데이터 뷰브가 연구되었으며, 데이터 큐브 계산의 고비용 문제점을 해결하기 위하여 큐브의 일부 영역만을 계산하는 빙산 큐브가 등장하였다. 빙산 큐브는 저장 공간의 감소, 집중적인 분석 등의 장점이 있으나, 여전히 많은 계산과 저장 공간을 필요로 하는 단점이 있다. 본 논문에서는 이러한 문제점을 해결하는 실용적인 방법으로 대용량 문제를 분산하여 처리하는 분산 병렬 컴퓨팅 기술인 맵리듀스(MapReduce) 프레임워크를 사용하여 분산 병렬 빙산 큐브인 MR-Naive와 MR-BUC 알고리즘을 제안한다. 실험을 통해 맵리듀스 프레임워크를 통한 빙사 큐브 계산이 효율적으로 분산 병렬 처리 됨을 확인하였다.
- 이수안, 문양세, 김진호
- 정보통신산업진흥원 주간기술동향 제1445호
- 2010년 5월 12일
Abstract
IT 기술의 발전으로 기업들의 비즈니스 관련 데이터는 기하급수적으로 늘어나고 있다. 특히 인터넷 기술의 발달은 기업의 비즈니스 모델까지 변화 시켰고, 시장은 역동적으로 변화를 요구한다. 인터넷 기술을 통해 높은 확장성과 가상화된 IT 자원을 서비스하는 클라우드 컴퓨팅은 쉽고 적은 비용으로 인프라 구축을 가능하게 한다.
클라우드 컴퓨팅을 활용한 비즈니스 인텔리전스는 기존의 기업 비즈니스 인텔리전스의 한계점인 속도, 실시간 데이터, 외부 데이터 연계 그리고 사용자층의 확대 등을 개선하고, 사용자의 요구에 맞는 혁신적이고 역동적인 환경을 제공할 것이다. 클라우드 컴퓨팅의 특성을 이용한 비즈니스 인텔리전스는 저비용으로 구축이 가능하고, 컴퓨팅 자원의 확장에 유연하며, BI 애플리케이션 개발 시간과 비용의 감소가 가능하다.
클라우드 비즈니스 인텔리전스는 기업이 급변하는 비즈니스 환경 속에서 쉽게 대처하고, 빠른 시장에서 심층적인 분석을 통해 신속한 의사결정으로 수익성 있는 성장을 가능하게 하며, 앞으로 기업의 미래를 결정하는 중요 요소로 자리 잡을 것이다.
- 김진호, 이수안, 민두환, 김석훈, 남시병
- 학술 심포지움 논문집, 한국정보과학회
- 2009년 6월
Abstract
유비쿼터스 센서 네트워크를 이용하여 건물 화재 모니터링 시스템을 개발할 때, 대형 건물에 대한 방재 관련 정보와 센싱된 데이터를 통한 감시, 화재 위험요소에 대한 정보를 모니터해야 한다. 이 연구에서는 센서 네트워크에서 스트림 형태로 들어오는 화재 모니터링 데이터를 다양하게 분석하고 감시하는데 사용하기 위한 데이터베이스를 설계하였다. 다양한 관점에서 데이터를 모니터링하고 분석할 수 있도록 여러가지 차원을 기준으로 스타 스키마 형태의 다차원 구조로 설계하였다.
- Jinho Kim, Donghoo Kim, Suan Lee, Yang-Sae Moon, Il-Yeol Song, Ritu Khare, and Yuan An
- International Conference on Conceptual Modeling
- 2009
Abstract
This paper presents a tool that automatically generates multidimensional schemas for data warehouses from OLTP entity-relationship diagrams (ERDs). Based on user’s input parameters, it generates star schemas, snowflake schemas, or a fact constellation schema by taking advantage of only structural information of input ERDs. Hence, SAMSTARplus can help users reduce efforts for designing data warehouses and aids decision making.
- Il-Yeol Song, Ritu Khare, Yuan An, Suan Lee, Sang-Pil Kim, Jinho Kim, and Yang-Sae Moon
- International Conference on Conceptual Modeling. Springer Berlin Heidelberg
- 2008
Abstract
While online transaction processing (OLTP) databases are modeled with Entity-Relationship Diagrams (ERDs), data warehouses constructed from these OLTP DBs are usually represented as star schema. Designing data warehouse schemas, however, is very time consuming. We present a prototype system, SAMSTAR, which automatically generates star schemas from an ERD. The system takes an ERD drawn by ERwin Data Modeler as an input and generates star schemas. SAMSTAR uses the Connection Topology Value [1] which is the syntactic structural information embedded in an ERD. SAMSTAR displays the resulting star schemas on a computer screen graphically. With this automatic generation of star schema, this system helps designers reduce their efforts and time in building data warehouse schemas.
Keywords
Prototype System, Automatic Generation, Automatic Tool, Connection Topology, Document Object Model
- 이수안, 김진호, 신성현, 남시병
- 전자공학회논문지, 대한전자공학회
- 2009년 05월
Abstract
유비쿼터스 센서 네트워크를 통해 수집되는 데이터는 끊임없이 변화하는 스트림 데이터이다. 이 스트림 데이터는 기존의 데이터베이스와는 매우 다른 특성을 가지고 있어서, 이를 저장하고 분석 및 질의 처리하는 방법에 대한 새로운 기법이 필요하며, 이에 대한 연구가 최근에 많은 관심을 끌고 있다. 본 연구에서는 센서 네트워크로부터 끊임없이 들어오는 스트림 데이터를 수집하고 이를 효율적으로 데이터베이스에 저장하는 저장 관리자를 구현하였다. 이 저장 관리자는 무선 센서 환경에서 발생하는 오류에 대한 정제, 반복적으로 센싱되는 동일한 데이터에 대한 축소 기능, 장기간의 스트림 데이터를 경동 시간 구조로 유지하는 기능 등을 제공한다. 또 이 연구에서는, 구현된 저장 관리자를 건물의 온도, 습도, 조도 등을 수집하는 건물 화재 감시 센서 네트워크에 적용하여 그 성능을 측정하였다. 실험 결과, 이 저장 관리자는 스트림 데이터의 저장 공간을 현저히 줄이며, 건물 화재 감시를 위한 장기간의 스트림 데이터를 저장하는데 효과적임을 보였다. Stream data, gathered from ubiquitous sensor networks, change continuously over time. Because they have quite different characteristics from traditional databases, we need new techniques for storing and querying/analyzing these stream data, which are research issues recently emerging . In this research, we implemented a storage manager gathering stream data and storing them into databases, which are sampled continuously from sensor networks. The storage manager cleans faulty data occurred in mobile sensors and it also reduces the size of stream data by merging repeatedly-sampled values into one and by employing the tilted time frame which stores stream data with several different sampling rates. In this research, furthermore, we measured the performance of the storage manager in the context of a sensor network monitoring fires of a building. The experimental results reveal that the storage manager reduces significantly the size of storage spaces and it is effective to manage the data stream for real applications monitoring buildings and their fires.
Keywords
유비쿼터스 센서 네트워크, 스트림 데이터, 저장 관리자, 경동 시간 구조, 데이터 축소
- Sung-Hyun Shin, Yang-Sae Moon, Jinho Kim, Soo-Ahn Lee, and Sang-Wook Kim
- International Conference on Information and Knowledge Engineering (IKE'08)
- 2008
Abstract
To support effective analyses in various business applications, On-Line Analytical Processing (OLAP) systems often represent multidimensional data as the horizontal format of tables whose columns are corresponding to values of dimension attributes. (Cross tabulation for statistical data is an example of horizontal tabular form.) These horizontal tables can have a lot of columns. Because conventional DBMSs have the limitation on the maximum number of attributes which tables can have (MS SQLServer and Oracle permit each table to have up to 1,024 columns), horizontal tables cannot be often stored directly into relational database systems. In that case, horizontal tables can be represented by equivalent vertical tables with the form of
Keywords
Multidimensional Data, Data Warehouse, PIVOT operation, Query Optimization
- Hea-Suk Kim, Yang-Sae Moon, Jinho Kim, Suan Lee, and Woong-Kee Loh
- International Conference. on e-Learning, e-Business, Enterprise Information Systems, and e-Government (EEE'08)
- 2008
Abstract
Students are educated in various ways such as private tutoring, academic institute lessons, educational broadcasting, and Internet learning sites as well as regular school lessons to promote their academic achievement. These learning methods can affect differently academic achievement over student groups. In this paper, we analyze the effect of learning methods and living style of students during vacation on academic achievement using data mining techniques. To achieve this goal, we first identify various items of learning methods and living style which can affect academic achievement. Students are surveyed over these items through an Internet online site, and the data collected from students are stored into databases. We then present data filtering methods of these collected data to adopt data mining techniques. We also propose the methods of generating decision trees and association rules from the collected student data. Finally, we apply the proposed methods to middle school students in a city of Korea, and we analyze the effect of learning methods during vacation on their academic achievement. We believe that the analysis results presented in this paper would be helpful in establishing the guideline of living style and the studying plans for students during vacation.
Keywords
data mining, academic achievement, learning method, decision tree, association rules